アラート設定
演習の概要
このモジュールでは、プロジェクトのアプリケーションのアラートを設定します。
アラート設定の有効化
ROSAクラスターでは、ROSAの利用者が作成したプロジェクトで実行しているアプリケーションを対象とした、 アラート設定が可能です。アラート設定をする場合、利用者が作成したプロジェクトのモニタリングが有効になっている必要があります。
アラート設定を有効化するには、モニタリングの時と同様に、「openshift-user-workload-monitoring」プロジェクトの 「user-workload-monitoring-config」設定マップ(ConfigMap)を、 次のように末尾3行の「alertmanager: …」を追加して保存します。
| 本演習を自習している時以外、この設定を適用する必要はありません。 |
kind: ConfigMap
apiVersion: v1
metadata:
name: user-workload-monitoring-config
namespace: openshift-user-workload-monitoring
data:
config.yaml: |
prometheus:
retention: 30d
volumeClaimTemplate:
spec:
resources:
requests:
storage: 200Gi
alertmanager:
enabled: true
enableAlertmanagerConfig: trueアラート出力用のサンプルアプリケーションの作成
ユーザープロジェクトを対象としたカスタムアラートを利用するには、 Prometheusのフォーマットに沿ったメトリクスを出力するアプリケーションを作成しておく必要があります。 そのためのサンプルアプリがありますので、まずはこちらを適当なプロジェクトで作成します。
プロジェクトを選択して、OpenShiftクラスターのWebコンソール右上にある、「+」アイコンをクリックします。
| OpenShiftでは、このインタフェースからYAML/JSON形式のテキストを直接入力して、Podなどのリソースを作成できます。 |
サンプルアプリケーションを実行するための、次のYAML形式のテキストを入力して「作成」をクリックします。 これによって、レプリカ数2の「prometheus-example-app」Podが実行されます。 また、PrometehusメトリクスをOpenShiftクラスター内部で見るために利用する「prometheus-example-app」 Serviceも、同時に作成しています。
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: prometheus-example-app
name: prometheus-example-app
spec:
replicas: 2
selector:
matchLabels:
app: prometheus-example-app
template:
metadata:
labels:
app: prometheus-example-app
spec:
containers:
- image: quay.io/brancz/prometheus-example-app:v0.2.0
imagePullPolicy: IfNotPresent
name: prometheus-example-app
---
apiVersion: v1
kind: Service
metadata:
labels:
app: prometheus-example-app
name: prometheus-example-app
spec:
ports:
- port: 8080
protocol: TCP
targetPort: 8080
name: web
selector:
app: prometheus-example-app
type: ClusterIP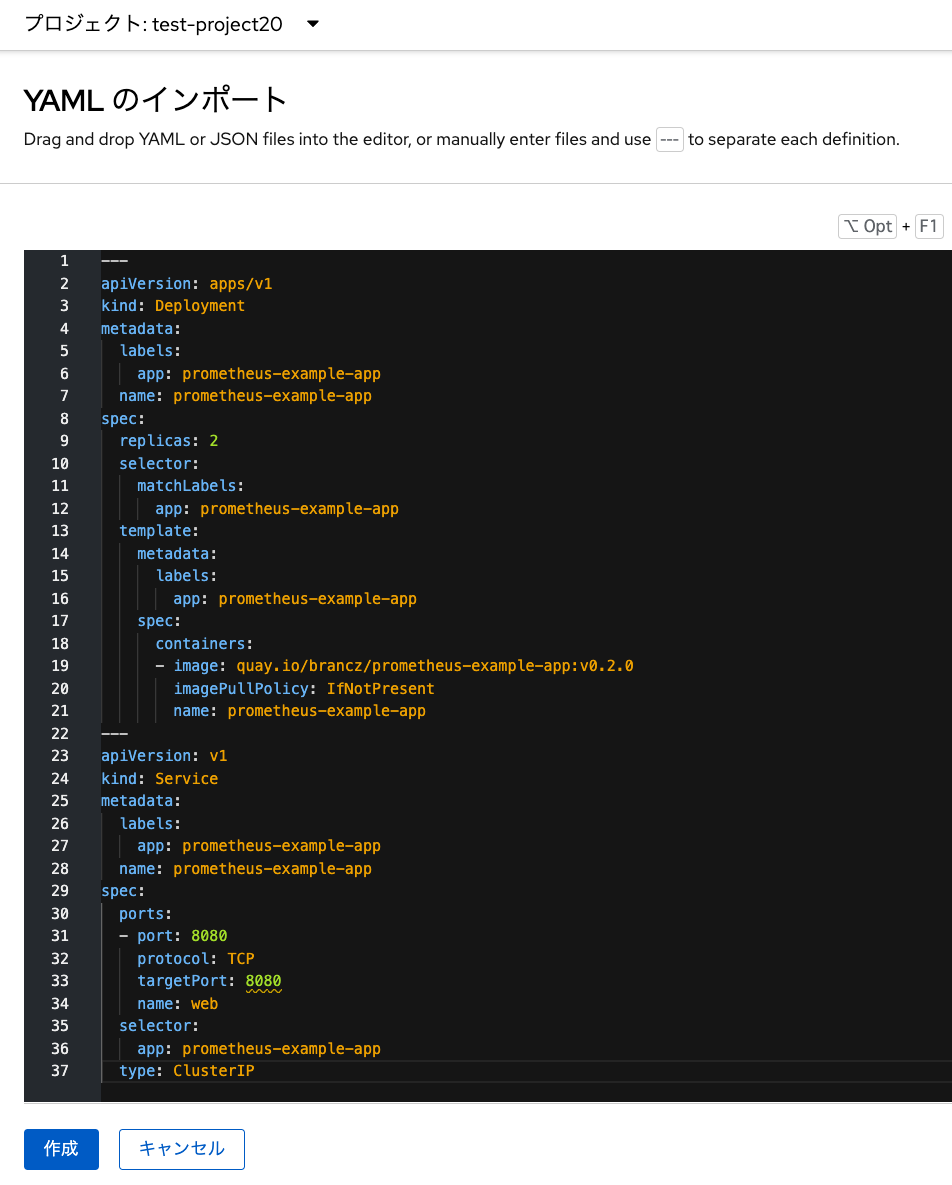
ServiceMonitorの作成
「prometheus-example-app」Serviceを利用したモニタリングのための、
Kubernetesカスタムリソース
としてServiceMonitorというリソースが、OpenShiftでは利用できるようになっています。
これを cluster-admin などの管理者アカウントで作成します。
ローカルユーザーでログインしている場合は、管理者アカウントで再ログインします。
先ほどYAML形式のテキストを入力した時と同様に、 「+」アイコンをクリックしてServiceMonitorを作成します。 「interval: 30s」で、メトリクスデータをスクレイピング(収集・加工)する間隔を30秒と設定しています。 また、「selector」を指定して、「app: prometheus-example-app」ラベルを持つServiceを対象としています。
| 「prometheus-example-app」Serviceを作成したプロジェクトに、このServiceMonitorを作成します。 |
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: prometheus-example-monitor
name: prometheus-example-monitor
spec:
endpoints:
- interval: 30s
port: web
scheme: http
path: /metrics
selector:
matchLabels:
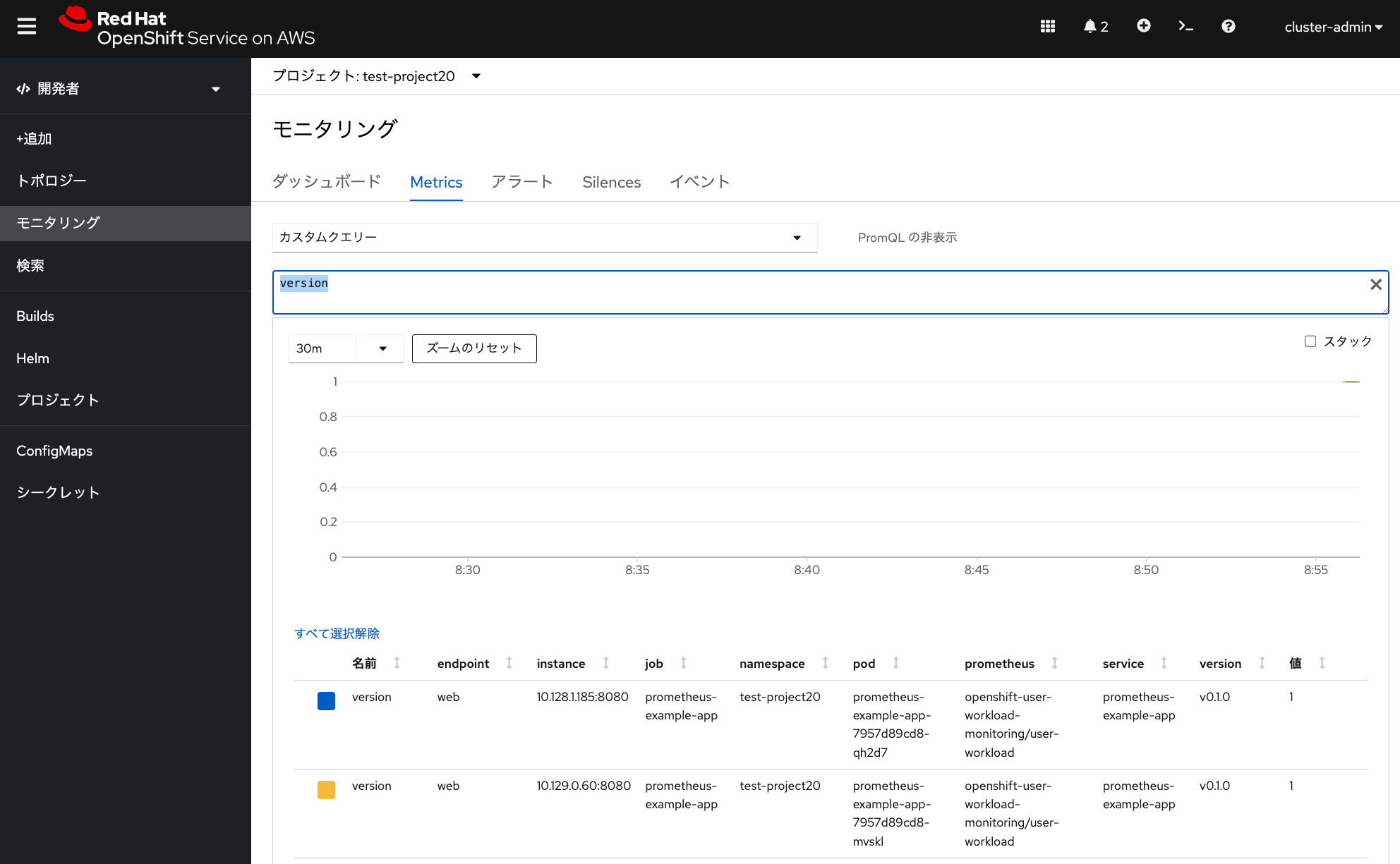
app: prometheus-example-appここまでの設定により、「モニタリング」メニューの「Metrics」タブから、 このサンプルアプリケーションにあるメトリクスを見れるようになります。 「Metrics」タブから「カスタムクエリー」を選択して、「version」を入力してEnterキーを押します。 すると、次のようなメトリクスを確認できます。
アラートルールの作成
簡単なアラートルールを作成してみます。OpenShiftではアラートルール作成のための、 KubernetesカスタムリソースであるPrometheusRuleが利用できるようになっています。 1つ以上のPodがダウンしたときに、アラートを発行する設定としてみます。
このサンプルアプリのPodの同時実行数は2となるので、「version」の値の合計値が「2」となっています。 そこで、1つ以上Podがダウンしたときの「version」の値の合計値が1(2未満)になるか、 または、全てのPodがダウンして「version」メトリクスが取得できない場合を想定した条件式を「expr:」で設定します。 「for: 30s」では、アラート発行のための条件式が真となって、アラートが「保留中」状態から「実行中」 状態になるまでの時間を30秒と設定しています。
| このPrometheusRuleも、ServiceMonitorを作成したプロジェクトを選択して、 管理者アカウントでYAMLテキストを直接入力して作成します。 |
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: example-alert
spec:
groups:
- name: prometheus-example-app-down
rules:
- alert: PrometheusExampleAppDown
annotations:
description: One or more example pods down.
summary: Example Pods Down.
expr: sum(version) < 2 or absent(version)
for: 30s
labels:
severity: warning作成したアラートルールや、それに伴ったアラート状態は、管理者アカウントでログインしている場合、 「モニタリング」メニューの「アラートタブ」から確認できます。 右側にある「・」が3つ縦に並んだアイコンをクリックして、「アラートルールの表示」をクリックすることで、 「アラートルールの詳細」を確認できます。
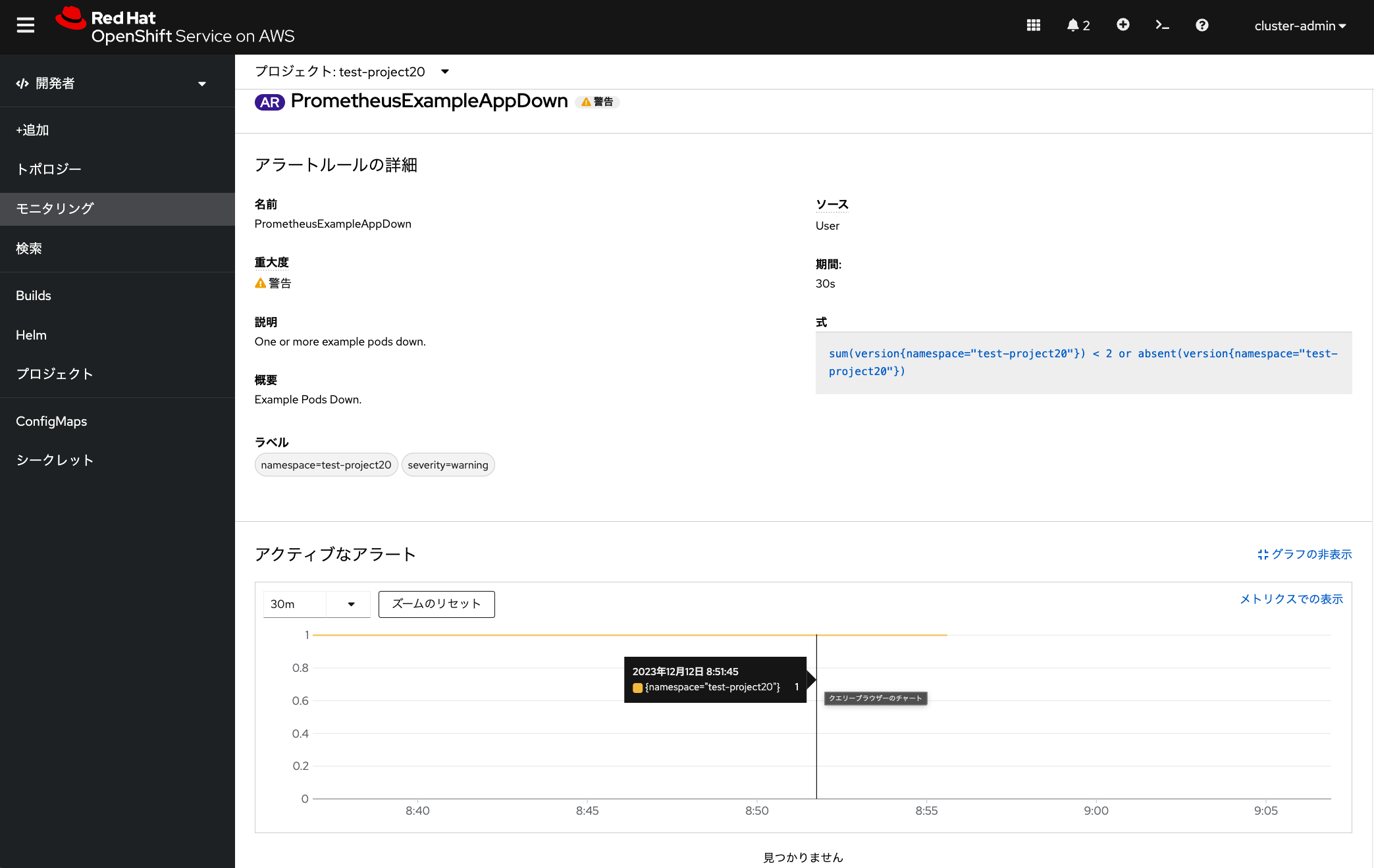
アラートのテスト
アラートをテストしてみます。 「トポロジー」メニューから、「prometheus-example-app」アプリケーションを選択して、 詳細タブから「↓矢印」を1回クリックして、Podの数を1つ減らします。
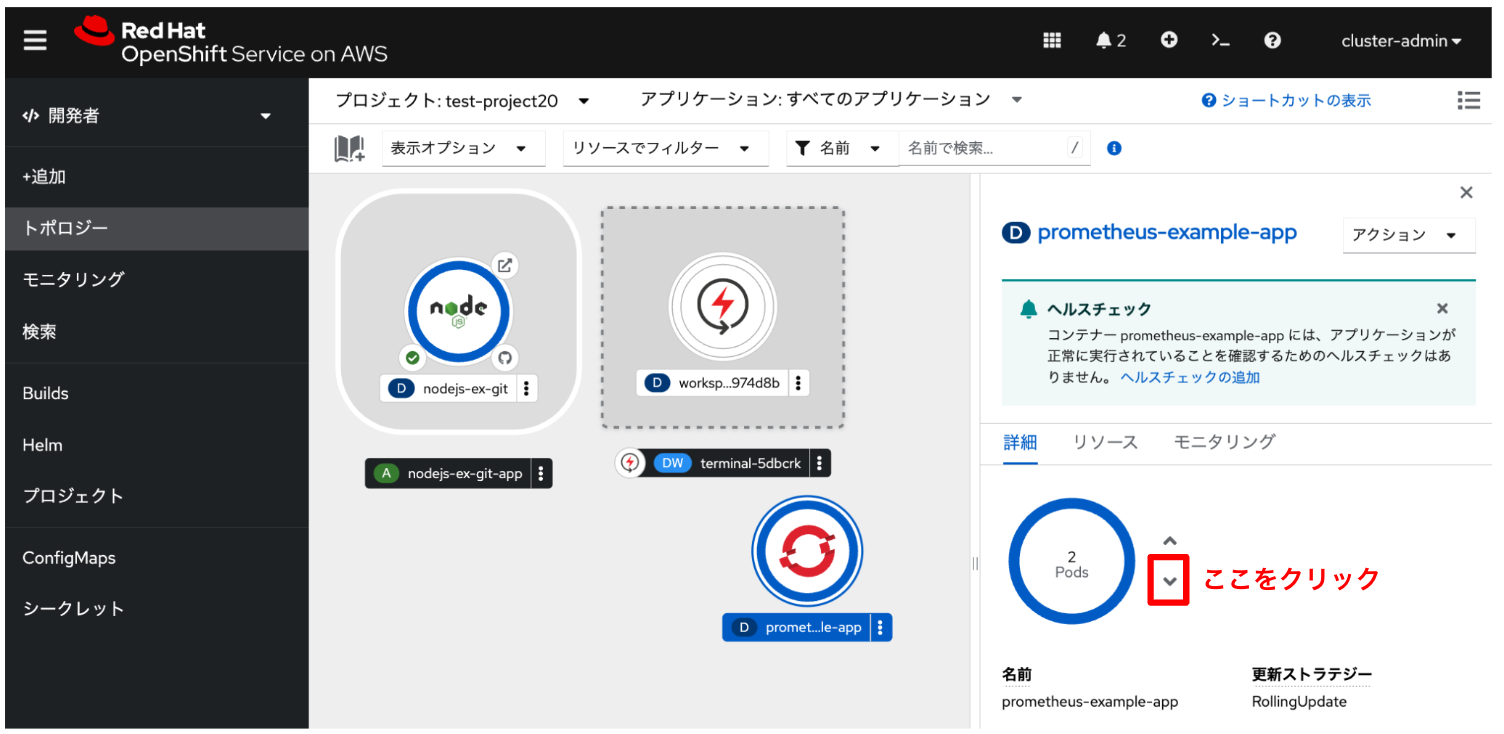
これにより、アラート状態が「実行中」に変わります。 管理者アカウントでログインしている場合、「モニタリング」メニューの「アラート」タブから確認できます。 「One or more example pods down」をクリックすると、アラートの詳細を確認できます。
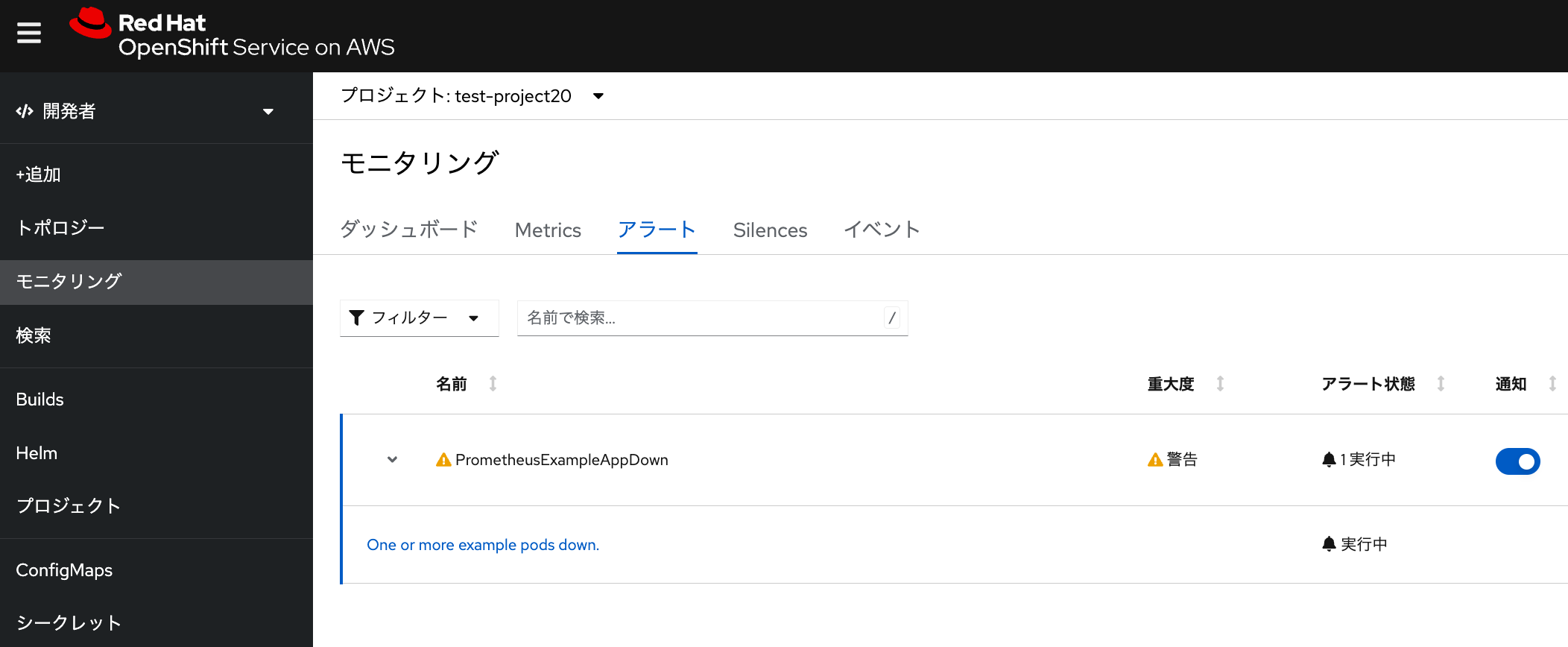
| 「通知」にあるスイッチをOFFにすると、アラートをサイレンス状態にできます。 また、アラートをCLIで確認したい場合は、 こちらのページにある情報を参考にしてください。 |
「トポロジー」メニューから サンプルアプリのPod数を再度2に戻す(Podの詳細タブの「↑」矢印をクリック)と、 アラート状態が「実行中」から、もともとの何もない状態に戻ります。
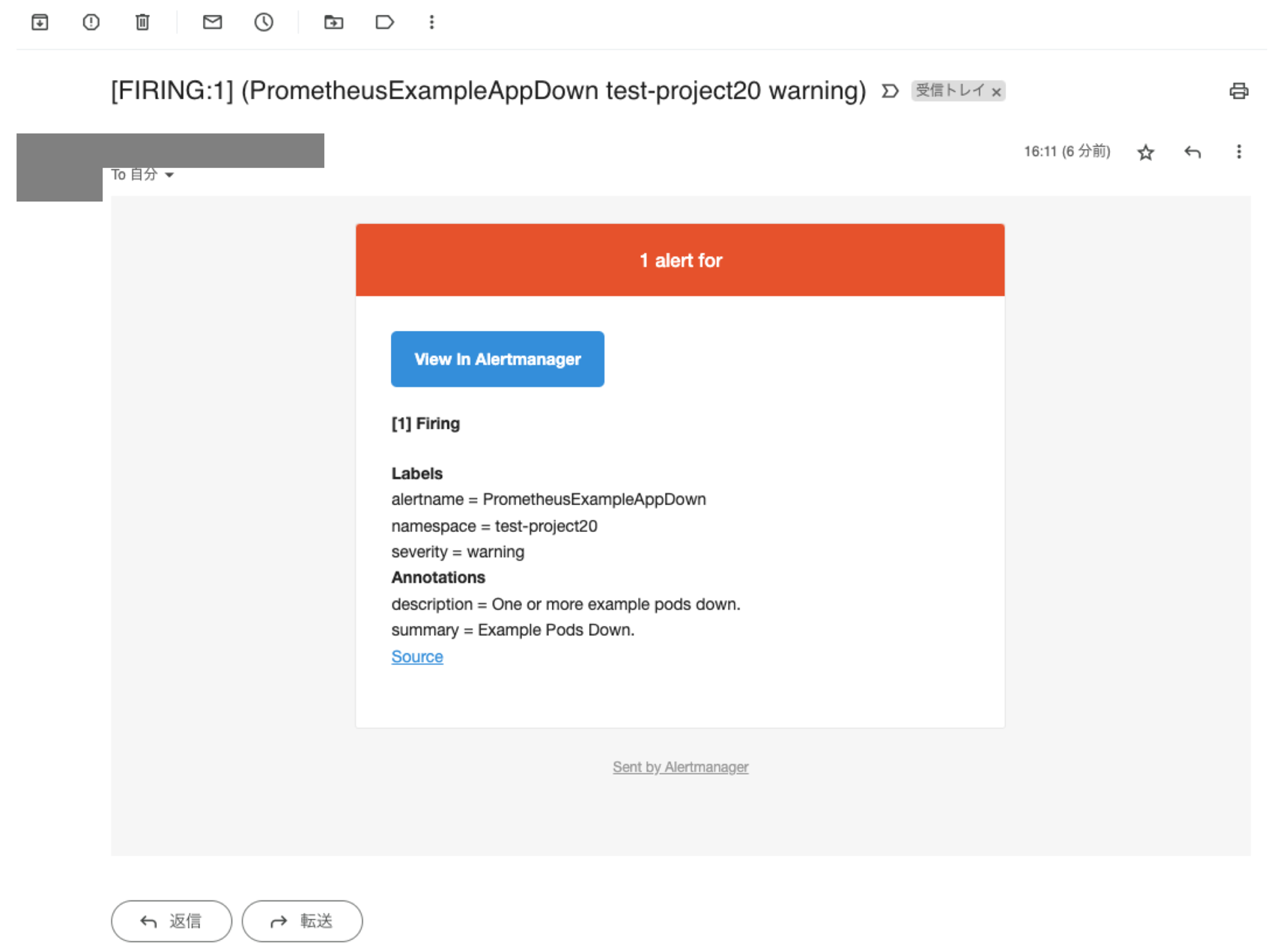
ROSAやOpenShiftでは、アラートを下記の外部システムに送信できます。
-
PagerDuty
-
Webhook
-
Email
-
Slack
Gmailに届いたアラートメールの例は、下記の画像のようになります。アラート送信の設定方法については、 公式ドキュメントをご参照ください。