Amazon Bedrockアプリケーションの実行
演習の概要
このモジュールでは、Amazon Bedrockを利用するためのサンプルアプリケーションを実行します。
このモジュールは、次の2つのAWSブログを元ネタにしています。 これらのブログを参照しつつ、ROSA HCPクラスターで動かすための差分となる情報を紹介していきます。
| 東京リージョン(ap-northeast-1)のAmazon Bedrockで、Claude 3の基盤モデルへのアクセスが許可されている状態を前提とします。Amazon Bedrock基盤モデルへのアクセス管理ガイドは、 こちらのWebページをご参照ください。本演習を自習している時以外、Amazon Bedrock基盤モデルへのアクセス許可の設定は必要ありません。 |
[デモ] Amazon Bedrockを利用するためのサンプルアプリケーション
| このコンテンツを実行する必要はありません。 |
上記の1つめのブログで紹介されているアプリケーションを変更します。 このブログでは、Amazon BedrockのClaude 1モデルを利用するためのサンプルコード(app.py)を 紹介していますが、最新の Claude 3モデルを利用するためのコードに変更してみます。
-
Amazon BedrockのClaude 3 Haikuモデルを利用するアプリケーションのコードの例 (app.py)
import streamlit as st
import boto3
import json
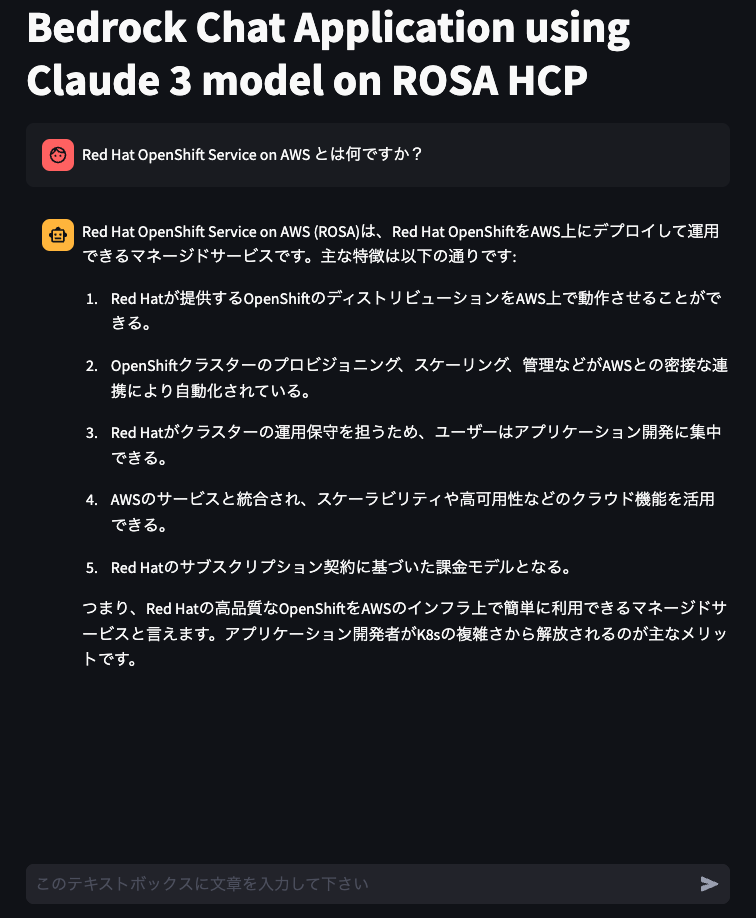
st.title("Bedrock Chat Application using Claude 3 model on ROSA HCP")
# Bedrock Runtimeサービス用のクライアント
bedrock = boto3.client(
service_name='bedrock-runtime',
region_name='ap-northeast-1')
def format_chat_history(messages):
formatted_history = ""
for message in messages:
# ユーザーかアシスタントかに応じてロールを設定
role = "Human:" if message["role"] == "user" else "Assistant:"
# メッセージを整形して追加
formatted_history += f"{role} {message['content']}\n"
return formatted_history
# チャット履歴の初期化
if "messages" not in st.session_state:
st.session_state.messages = []
# アプリ再実行時にチャットメッセージを表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# ユーザー入力の受け取り
if prompt := st.chat_input("このテキストボックスに文章を入力して下さい"):
# ユーザーメッセージをチャットメッセージコンテナに表示
with st.chat_message("user"):
st.markdown(prompt)
# ユーザーメッセージをチャット履歴に追加
st.session_state.messages.append({"role": "user", "content": prompt})
# 対話履歴を整形してモデルの入力用に準備
chat_history = format_chat_history(st.session_state.messages)
# アシスタントの応答をチャットメッセージコンテナに表示
with st.chat_message("assistant"):
message_placeholder = st.empty()
full_response = ""
# 整形された対話履歴と新しいユーザー入力をモデルに送信
body = json.dumps({
'max_tokens': 1000,
"messages": [{"role": "user", "content": prompt}],
"anthropic_version": "bedrock-2023-05-31"
})
accept = 'application/json'
contentType = 'application/json'
model_id = 'anthropic.claude-3-haiku-20240307-v1:0'
#model_id = 'anthropic.claude-3-5-sonnet-20240620-v1:0'
response = bedrock.invoke_model_with_response_stream(
body=body, modelId=model_id, accept=accept, contentType=contentType)
stream = response.get('body')
for event in stream:
chunk = event.get('chunk')
if chunk:
# 取得したチャンクを追加し、Streamlitに表示
chunk_json = json.loads(chunk.get("bytes").decode())
if chunk_json["type"]=="content_block_delta":
full_response += str(chunk_json["delta"]["text"])
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
# アシスタントの応答をチャット履歴に追加
st.session_state.messages.append(
{"role": "assistant", "content": full_response})元のブログで紹介していたコードとの差分は下記です。
--- app.py.org 2024-08-08 12:14:31
+++ app.py 2024-08-08 12:13:57
@@ -2,7 +2,7 @@
import boto3
import json
-st.title("Bedrock Chat")
+st.title("Bedrock Chat Application using Claude 3 model on ROSA HCP")
# Bedrock Runtimeサービス用のクライアント
bedrock = boto3.client(
@@ -28,7 +28,7 @@
st.markdown(message["content"])
# ユーザー入力の受け取り
-if prompt := st.chat_input("What is up?"):
+if prompt := st.chat_input("このテキストボックスに文章を入力して下さい"):
# ユーザーメッセージをチャットメッセージコンテナに表示
with st.chat_message("user"):
st.markdown(prompt)
@@ -45,14 +45,14 @@
# 整形された対話履歴と新しいユーザー入力をモデルに送信
body = json.dumps({
- 'prompt': chat_history + 'Human: ' + prompt + '\n\nAssistant:',
- 'max_tokens_to_sample': 1000,
- "stop_sequences": ["\n\nHuman:"],
+ 'max_tokens': 1000,
+ "messages": [{"role": "user", "content": prompt}],
"anthropic_version": "bedrock-2023-05-31"
})
accept = 'application/json'
contentType = 'application/json'
- model_id = 'anthropic.claude-instant-v1'
+ model_id = 'anthropic.claude-3-haiku-20240307-v1:0'
+ #model_id = 'anthropic.claude-3-5-sonnet-20240620-v1:0'
response = bedrock.invoke_model_with_response_stream(
body=body, modelId=model_id, accept=accept, contentType=contentType)
@@ -62,8 +62,9 @@
chunk = event.get('chunk')
if chunk:
# 取得したチャンクを追加し、Streamlitに表示
- full_response += json.loads(chunk.get('bytes').decode()
- )["completion"]
+ chunk_json = json.loads(chunk.get("bytes").decode())
+ if chunk_json["type"]=="content_block_delta":
+ full_response += str(chunk_json["delta"]["text"])
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
# アシスタントの応答をチャット履歴に追加上記の差分を解説します。
-
サンプルアプリケーションのタイトルを変更
-
ユーザー入力を受け取るテキストボックスに表示される文字を変更
-
Claude 3の Message API を利用するように変更
-
モデルIDをClaude 3 Haikuに変更 (Claude 3.5 SonnetのモデルIDも参考として記載)
-
Claude 3の出力をJSON形式にデコードした情報からメッセージを抽出するように変更
Dockerfileとrequirements.txtは、元のブログに記載されていたものと同じです。 これらのソースコードを、下記のGitHubリポジトリにアップロードしています。
サンプルコードからアプリケーションをデプロイ
上記の変更を適用したサンプルコードを、ROSA HCPクラスターにデプロイします。 OpenShiftコンソールにログインして、「開発者」→「+追加」メニューから 「Gitからのインポート」をクリックします。
| 本演習をワークショップ形式で実施している場合、 サンプルアプリケーションをデプロイするプロジェクトには 「test」から始まる名前を付けてください。 |
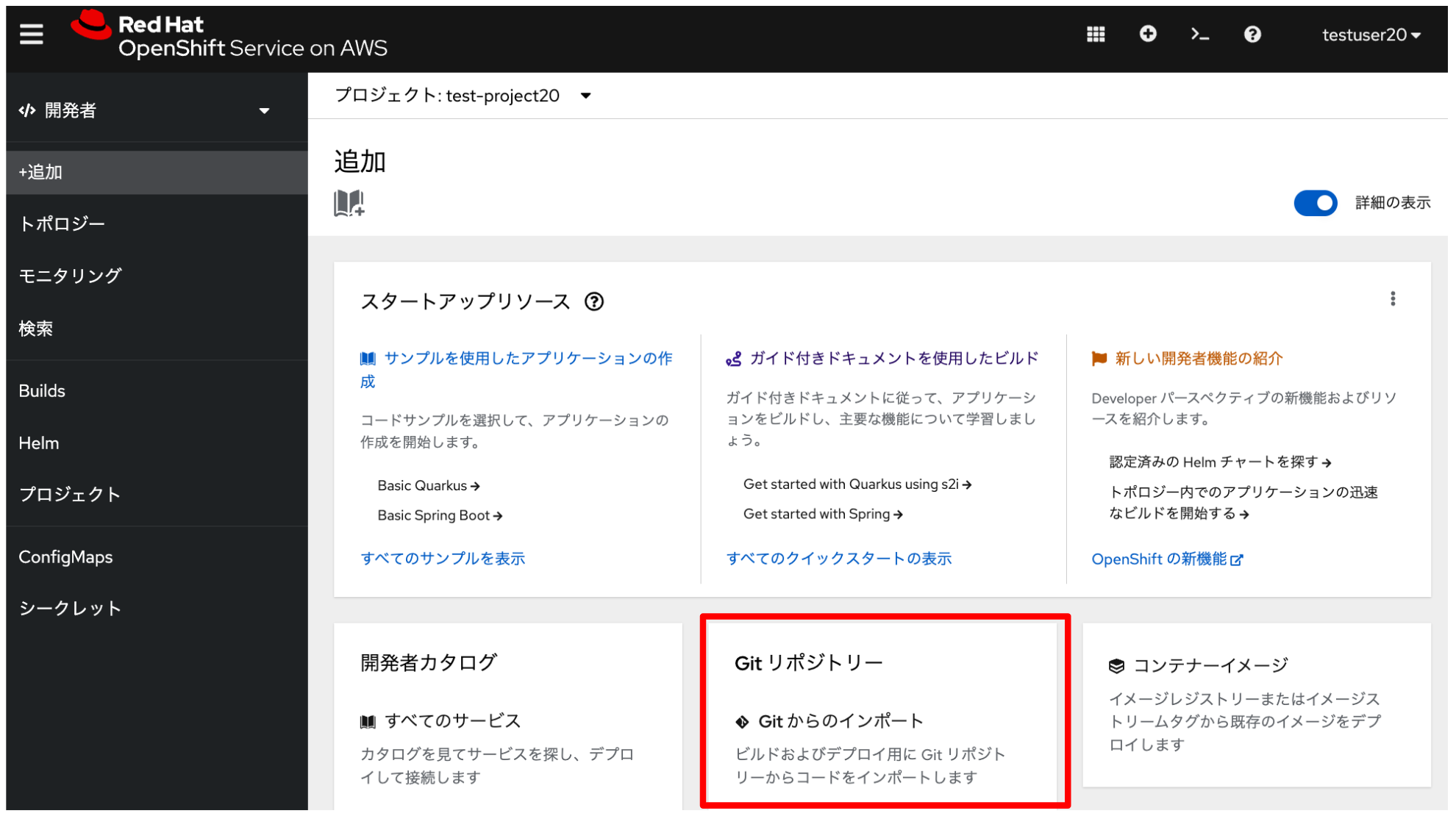
「GitリポジトリーのURL」に、下記のURLをコピーして貼り付けます。
https://github.com/h-kojima/sample-llm-aws/すると、次のような画面が表示されます。
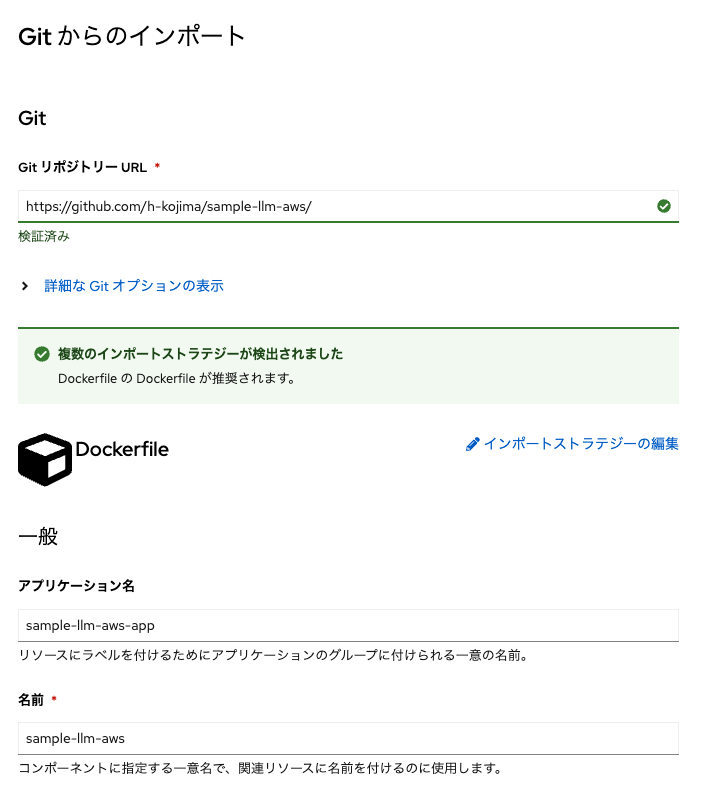
この画面を下にスクロールしていき、アプリケーション名に「sample-llm-aws-app」、名前に「sample-llm-aws」 ターゲットポートに「8501」を入力します。 このターゲットポートは、前述したコードのDockerfileでアプリケーション起動時に指定されています。
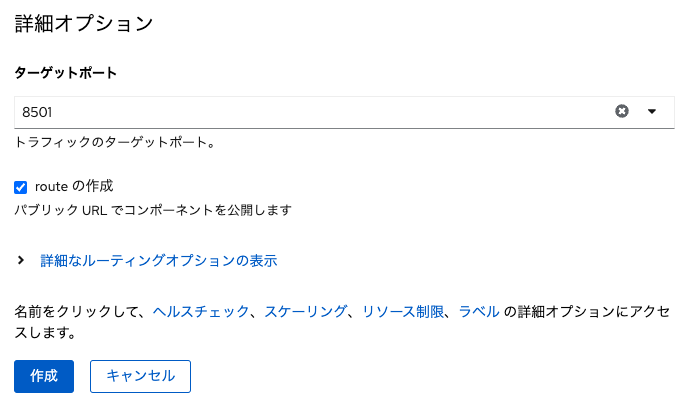
その他のパラメータは全てデフォルトのままで「作成」をクリックします。 これによって、Dockerfileの内容に従ってコンテナイメージの自動ビルドと、 ビルドされたコンテナイメージをベースにしたコンテナの自動デプロイが実行されます。
数分待つと、「開発者」→「トポロジー」メニューから、 サンプルアプリケーションのPodが「Running」状態になっていて、 正常に実行されたことを確認できるようになります。 赤四角で囲んである所をクリックして、サンプルアプリケーションのURLにアクセスします。
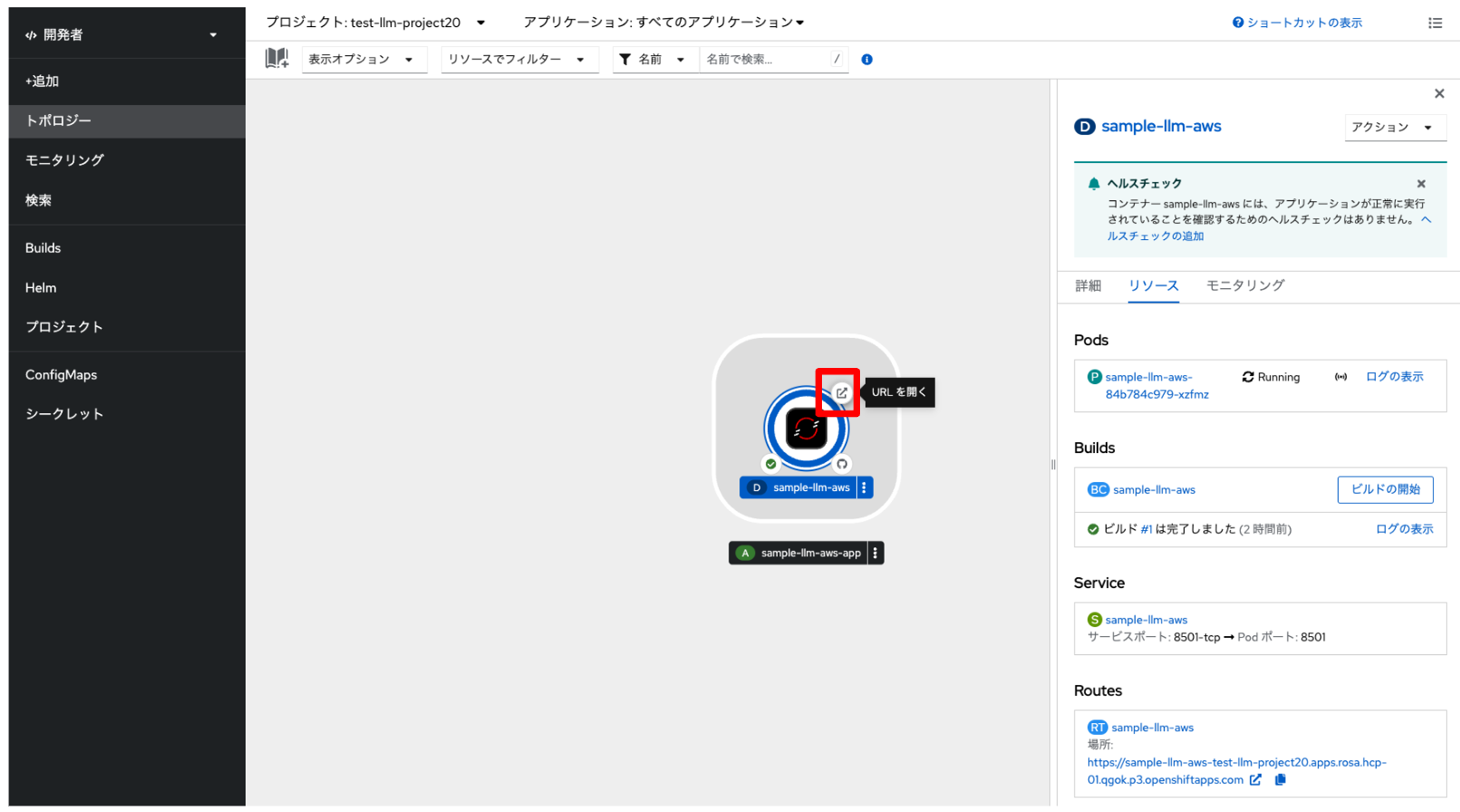
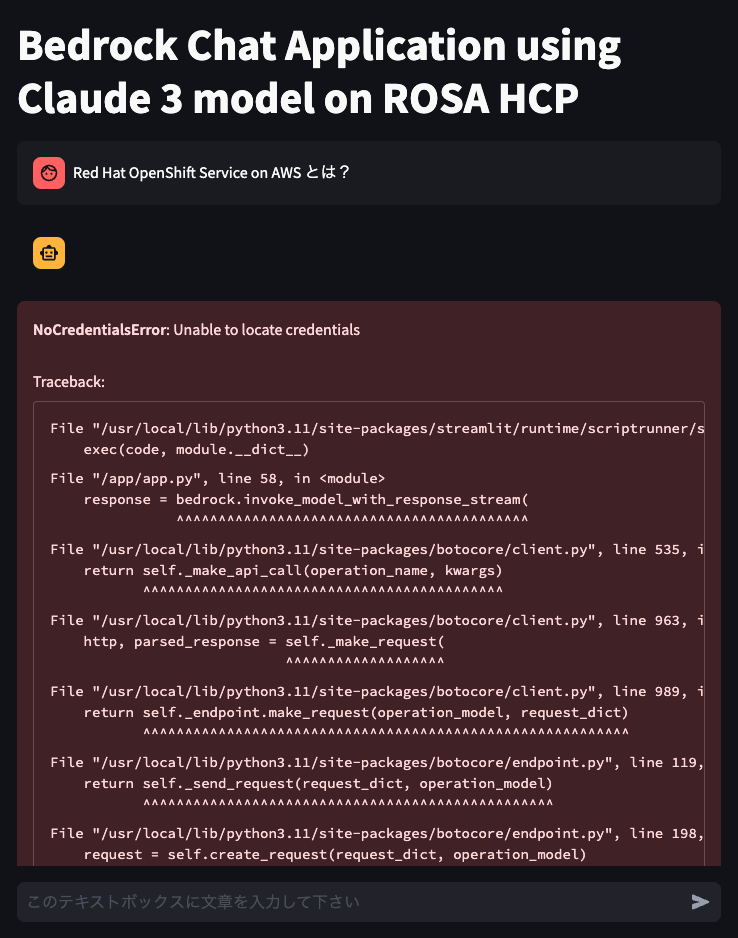
すると、次のようなサンプルアプリケーションの画面が表示されます。
この段階では、Bedrockを利用するための認証情報が無いため、テキストボックスに何か入力しても、
画面のように NoCredentialsError: Unable to locate credentials などが表示されるはずです。
[デモ] Amazon Bedrockを利用するためのIAMロールの作成
| 本演習を自習している時以外、この項目は実行しないで下さい。 |
デプロイしたアプリケーションがAmazon Bedrockを利用するための認証情報を追加します。 STS を用いた ROSA ワークロードのためのきめ細かい IAM ロール に記載してあるステップ1, 2, 4, 5を順番に実行して、次の「サービスアカウントの作成」で利用するIAMロールを作成します。これらのステップ実行時の注意点を記載します。
-
ステップ1で設定してある変数は、ご自身の利用している環境に応じて、適宜変更します。
APP_NAMESPACE変数は、前述の手順でデプロイしたアプリケーションのプロジェクト名(例:test-llm-project20など)を指定します。 またAWS_REGION変数は必要ありません。 -
ステップ2で実行する
ocCLIは、ROSA HCPクラスターの管理者アカウント(cluster-adminなど)で実行します。 -
ステップ3を実行する必要はありません。
-
ステップ5にあるIAMポリシーについて、元のブログではAmazon S3にアクセスするための IAMポリシーをアタッチしていますが、ここではAmazon BedrockにアクセスするためのIAMポリシーとして、
AmazonBedrockFullAccessを指定するようにします。
サービスアカウントの作成
アプリケーションをデプロイしているプロジェクトにサービスアカウントを作成します。 OpenShiftのコンソールに戻って、「管理者向け表示」→「ユーザー管理」→「ServiceAccounts」から、 「ServiceAccount の作成」をクリックします。
下記をコピペして貼り付けます。「XXXXX」となっているところは、 AWSアカウントIDに置き換えて「作成」をクリックします。 これで、Amazon Bedrockの認証情報として利用するための、 「bedrock-sa」という名前のサービスアカウントが作成されます。
| 本演習をワークショップ形式で実施している場合、 インストラクターがAWSのARNをご案内します。 本演習を自習している場合、前の手順で作成したIAMロールのARNに置き換えてください。 |
apiVersion: v1
kind: ServiceAccount
metadata:
name: bedrock-sa
annotations:
eks.amazonaws.com/role-arn: 'arn:aws:iam::XXXXXXXXXXXXXX:role/iam-app-bedrock-role-YYYYYYYYY'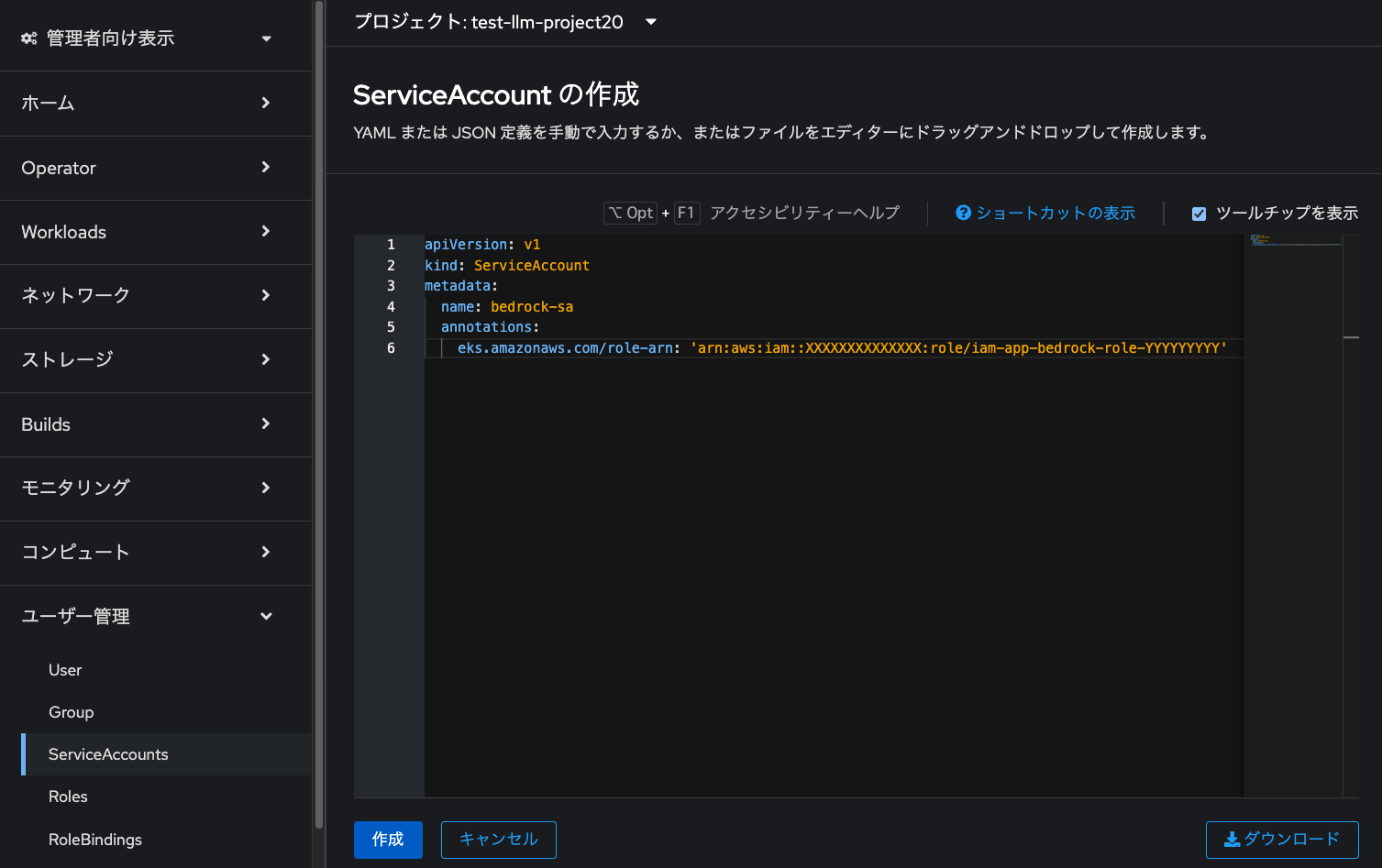
Deploymentにサービスアカウントの追加
OpenShiftのDeploymentリソースに、作成したサービスアカウントを追加します。 これで、既存のサンプルアプリケーションが、Amazon Bedrockの認証情報を利用できるようになります。
「Deployments」メニューから「sample-llm-aws」デプロイメントを選択して、 「YAML」タブから下記を「spec:」と「containers:」の間に挿入して「保存」をクリックします。
serviceAccount: bedrock-sa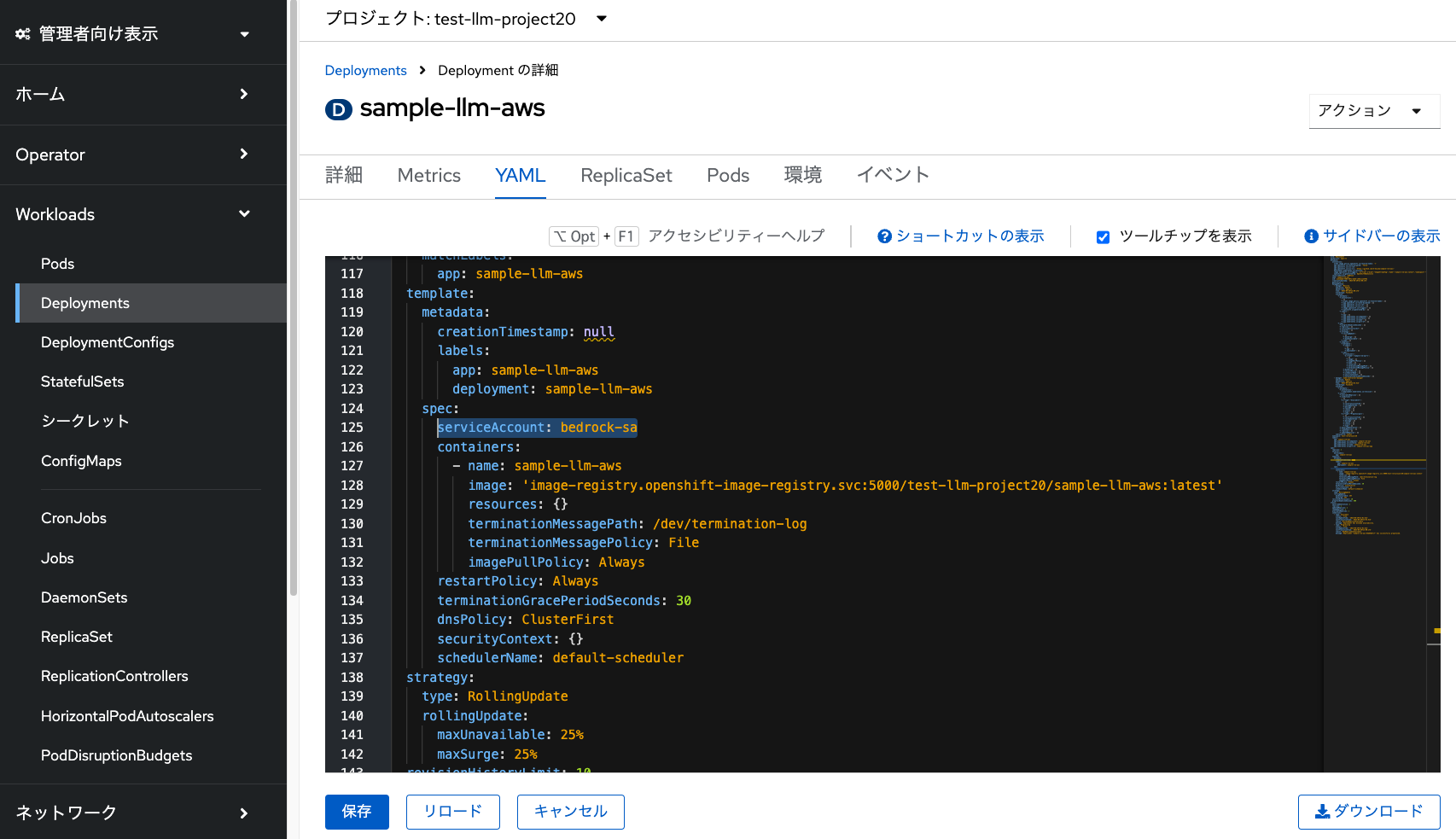
すると、Podが自動的に再デプロイされて、 Amazon Bedrockにアクセスするためのサービスアカウントを利用するための設定が追加されます。