Infra ノードの作成
本コンテンツは、MAD Workshop Ops Track の内容をベースに、一部変更しています。
演習の概要
OpenShiftのサブスクリプションモデルでは、顧客は追加料金なしで様々なコアインフラストラクチャコンポーネントをを実行できます。つまり、OpenShiftのコアインフラストラクチャコンポーネントのみを実行しているノードは、クラスター環境をカバーするために必要なサブスクリプションの総数にはカウントされません。
インフラストラクチャのカテゴライズに該当するOpenShiftコンポーネントは以下が含まれます。
-
kubernetesとOpenShiftのコントロールプレーンサービス("masters")。
-
ルータ
-
コンテナイメージレジストリ
-
クラスタメトリクスの収集 ("monitoring")
-
クラスタ集約型ロギング
-
サービスブローカー
上記以外のコンテナ/Pod/コンポーネントを実行しているノードはすべてワーカーとみなされ、サブスクリプションでカバーされている必要があります。
MachineSet 詳細
MachineSets の演習では、MachineSets を使用して、レプリカ数を変更してクラスタをスケーリングすることを検討しました。インフラストラクチャノードの場合、特定のKubernetesラベルを持つ Machine を追加で作成したいと思います。そして、それらのラベルを持つノード上で特定の動作をするように様々なインフラストラクチャコンポーネントを設定することができます。
現在、インフラストラクチャコンポーネントの制御に使用されているOperatorは、"taint" と "toleration" の使用をすべてサポートしているわけではありません。これは、インフラストラクチャのワークロードはインフラストラクチャノード上で実行されますが、他のワークロードがインフラストラクチャノード上で実行されることは特に禁止されていないことを意味します。言い換えれば、すべてのOperatorに taint/toleration が完全に実装されるまでは、ユーザワークロードとインフラストラクチャワークロードが混在する可能性があります。
taint/tolerationの使用は、これらの演習ではカバーされていません。
これを実現するために、MachineSets を追加で作成します。
MachineSets がどのように動作するかを理解するために、手順を進めていきましょう。
CLUSTERNAME=$(oc get infrastructures.config.openshift.io cluster -o jsonpath='{.status.infrastructureName}')
ZONENAME=$(oc get nodes -L topology.kubernetes.io/zone --no-headers | awk '{print $NF}' | tail -1)
oc get machineset -n openshift-machine-api -o yaml ${CLUSTERNAME}-worker-${ZONENAME}Metadata
MachineSet の metadata には、MachineSet の名前や、様々なラベルのような情報が含まれています。
metadata:
annotations:
machine.openshift.io/GPU: "0"
machine.openshift.io/memoryMb: "65536"
machine.openshift.io/vCPU: "16"
creationTimestamp: "2023-06-19T03:17:34Z"
generation: 3
labels:
machine.openshift.io/cluster-api-cluster: cluster-zbwlg-cbgq7
name: cluster-zbwlg-cbgq7-worker-us-east-2a
namespace: openshift-machine-api
resourceVersion: "95996"
uid: 73341b44-0495-46c5-b6a2-90aa2650de3cMachineAutoScaler が定義されている MachineSet をダンプした場合、MachineSet に annotation が表示されるかもしれません。
Selector
MachineSet は Machine の作成方法を定義し、Selector はどのマシンがそのセットに関連付けられているかをOperatorに指示します。
spec:
replicas: 3
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: cluster-zbwlg-cbgq7
machine.openshift.io/cluster-api-machineset: cluster-zbwlg-cbgq7-worker-us-east-2aこの場合、クラスタ名は cluster-zbwlg-cbgq7 であり、セット全体のラベルが追加されています。
Template Metadata
template は、MachineSet の一部で、Machine をテンプレート化するものです。
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: cluster-zbwlg-cbgq7
machine.openshift.io/cluster-api-machine-role: worker
machine.openshift.io/cluster-api-machine-type: worker
machine.openshift.io/cluster-api-machineset: cluster-zbwlg-cbgq7-worker-us-east-2aTemplate Spec
template は、Machine/Node をどのように作成するかを指定する必要があります。
spec、より具体的には、providerSpec には、Machine を正しく作成してブートストラップするための重要なAWSデータがすべて含まれていることに気づくでしょう。
この例では、結果として得られるノードが1つ以上の特定のラベルを継承していることを確認したいと思います。上の例で見たように、ラベルは metadata セクションにあります。
spec:
lifecycleHooks: {}
metadata: {}
providerSpec:
value:
ami:
id: ami-01af87a6ecc18023d
...デフォルトでは、インストーラが作成する MachineSets は、ノードに追加のラベルを適用していません。
カスタムMachineSetの定義
既存の MachineSet を分析したところで、次は Infra ノードの MachineSet のマニフェストを作成していきます。
まずは必要なパラメータを取得します。
export AMI=$(oc get machineset -n openshift-machine-api -l 'machine.openshift.io/os-id!=Windows' -o jsonpath='{.items[0].spec.template.spec.providerSpec.value.ami.id}')
export CLUSTERID=$(oc get infrastructures.config.openshift.io cluster -o jsonpath='{.status.infrastructureName}')
export REGION=$(oc get infrastructures.config.openshift.io cluster -o jsonpath='{.status.platformStatus.aws.region}')
echo $CLUSTERID
echo $REGION
echo $AMI以下のテンプレートを、上記で取得した値に置換して、マニフェストを完成させます。 ※Terapadなどテキストツールにコピー&ペーストして、全て置換してください。
-
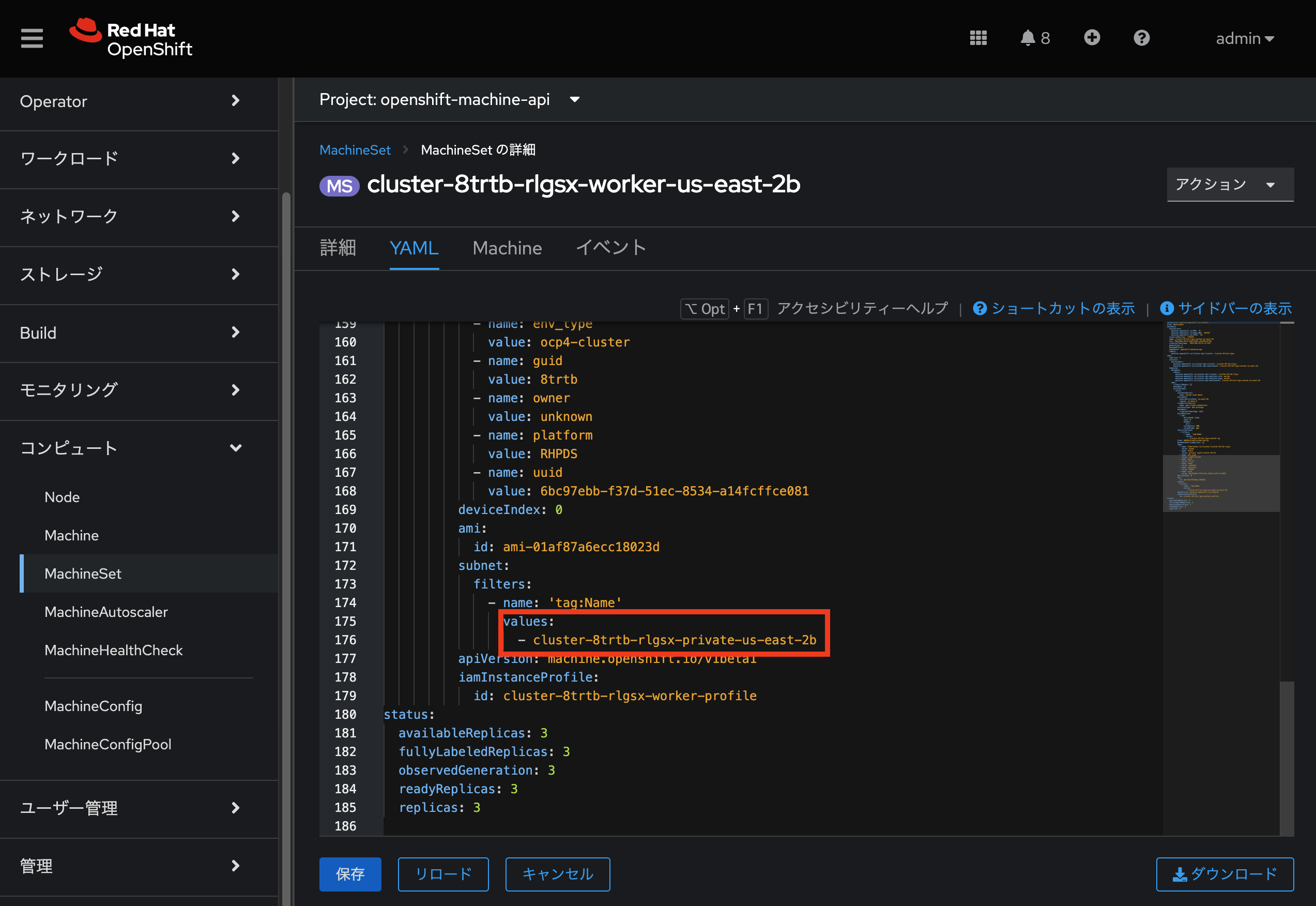
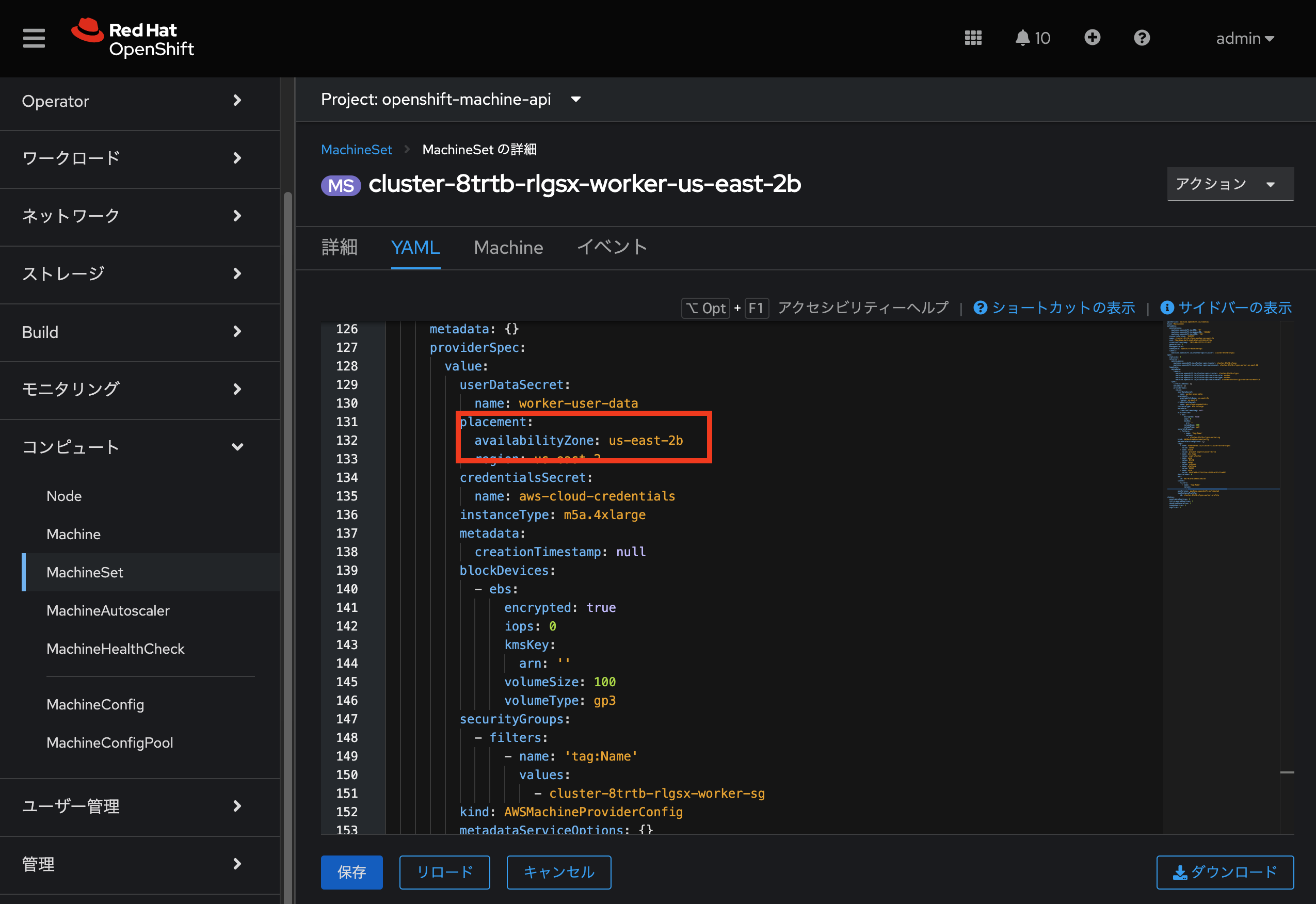
cluster-zbwlg-cbgq7-private-us-east-2a→ subnet情報。既存の Worker 用 MachineSets から取得(下図参照。ここでは cluster-8trtb-rlgsx-private-us-east-2b) -
us-east-2a→ AZ情報。既存の Worker 用 MachineSets から取得(ここでは us-east-2b) -
us-east-2→ $REGION -
cluster-zbwlg-cbgq7→ $CLUSTERID -
us-east-2→ $REGION -
ami-01af87a6ecc18023d→ $AMI
---
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: cluster-zbwlg-cbgq7
machine.openshift.io/cluster-api-machine-role: infra
machine.openshift.io/cluster-api-machine-type: infra
name: cluster-zbwlg-cbgq7-infra-us-east-2a
namespace: openshift-machine-api
spec:
replicas: 0
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: cluster-zbwlg-cbgq7
machine.openshift.io/cluster-api-machineset: cluster-zbwlg-cbgq7-infra-us-east-2a
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: cluster-zbwlg-cbgq7
machine.openshift.io/cluster-api-machine-role: infra
machine.openshift.io/cluster-api-machine-type: infra
machine.openshift.io/cluster-api-machineset: cluster-zbwlg-cbgq7-infra-us-east-2a
spec:
metadata:
creationTimestamp: null
labels:
role: storage-node
node-role.kubernetes.io/worker: ""
providerSpec:
value:
ami:
id: ami-01af87a6ecc18023d
apiVersion: awsproviderconfig.openshift.io/v1beta1
blockDevices:
- ebs:
iops: 0
volumeSize: 120
volumeType: gp3
credentialsSecret:
name: aws-cloud-credentials
deviceIndex: 0
iamInstanceProfile:
id: cluster-zbwlg-cbgq7-worker-profile
instanceType: m5.4xlarge
kind: AWSMachineProviderConfig
metadata:
creationTimestamp: null
placement:
availabilityZone: us-east-2a
region: us-east-2
publicIp: null
securityGroups:
- filters:
- name: tag:Name
values:
- cluster-zbwlg-cbgq7-worker-sg
subnet:
filters:
- name: tag:Name
values:
- cluster-zbwlg-cbgq7-private-us-east-2a
tags:
- name: kubernetes.io/cluster/cluster-zbwlg-cbgq7
value: owned
userDataSecret:
name: worker-user-data
versions:
kubelet: ""今回のサンプルマニフェストは AWS 用のものです。環境に合わせたサンプルは link:https://docs.openshift.com/container-platform/4.12/machine_management/creating-infrastructure-machinesets.html [こちら]を参照しながら、適宜修正が必要です。
編集したマニフェストを作成し、oc create を実行します。
vi machineset-infra.yamloc create -f machineset-infra.yamlWeb コンソールから新しいMachinesetが作成されているか確認してみてください。
export MACHINESET=$(oc get machineset -n openshift-machine-api -l machine.openshift.io/cluster-api-machine-role=infra -o jsonpath='{.items[0].metadata.name}')
oc patch machineset $MACHINESET -n openshift-machine-api --type='json' -p='[{"op": "add", "path": "/spec/template/spec/metadata/labels", "value":{"node-role.kubernetes.io/worker":"", "node-role.kubernetes.io/infra":""} }]'
oc scale machineset $MACHINESET -n openshift-machine-api --replicas=2次のように実行します。
oc get machineset -n openshift-machine-api新しいインフラセットが以下例に似た名前で表示されているはずです。
NAME DESIRED CURRENT READY AVAILABLE AGE
cluster-zbwlg-cbgq7-infra-us-east-2a 2 2 2 2 49m
cluster-zbwlg-cbgq7-worker-us-east-2a 3 3 3 3 3d6hまだインスタンスが起動していてブートストラップを行っているため、セットの中には利用可能なマシンがありません。
インスタンスがいつ実行されるかは oc get machine -n openshift-machine-api で確認することができます。
次に oc get node を使って、実際のノードがいつ結合されて準備が整ったかを確認することができます。
Machine が準備されて Node として追加されるまでには数分かかることがあります。
oc get nodesNAME STATUS ROLES AGE VERSION
ip-10-0-136-135.us-east-2.compute.internal Ready worker 18h v1.25.7+eab9cc9
ip-10-0-141-135.us-east-2.compute.internal Ready infra,worker 3m31s v1.25.7+eab9cc9
ip-10-0-171-195.us-east-2.compute.internal Ready control-plane,master 28h v1.25.7+eab9cc9
ip-10-0-175-87.us-east-2.compute.internal Ready infra,worker 3m32s v1.25.7+eab9cc9
ip-10-0-178-255.us-east-2.compute.internal Ready worker 28h v1.25.7+eab9cc9
ip-10-0-209-191.us-east-2.compute.internal Ready worker 28h v1.25.7+eab9cc9どのノードが新しいノードなのか分からなくて困っている場合は、AGE カラムを見てみてください。
また、ROLES 列では、新しいノードが worker と infra の両方のロールを持っていることに気づくでしょう。
oc get nodes -l node-role.kubernetes.io/infraラベルを確認する
この例では、一番若いノードは ip-10-0-133-134.us-east-2.compute.internal という名前でした。
YOUNG_INFRA_NODE=$(oc get nodes -l node-role.kubernetes.io/infra --sort-by=.metadata.creationTimestamp -o jsonpath='{.items[0].metadata.name}')
oc get nodes ${YOUNG_INFRA_NODE} --show-labels | grep --color node-roleそして、LABELS の欄には、次のように書かれています。
beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=m5.2xlarge,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=us-east-2,failure-domain.beta.kubernetes.io/zone=us-east-2a,kubernetes.io/arch=amd64,kubernetes.io/hostname=ip-10-0-140-3,kubernetes.io/os=linux,node-role.kubernetes.io/infra=,node-role.kubernetes.io/worker=,node.openshift.io/os_id=rhcosnode-role.kubernetes.io/infra ラベルが確認できます。
Operator について
Operatorはただの Pods です。しかし 彼らは特別な Pods であり、Kubernetes環境でアプリケーションをデプロイして管理する方法を理解しているソフトウェアです。Operatorのパワーは、CustomResourceDefinitions (CRD)と呼ばれるKubernetesの機能に依存しています。CRD はまさにその名の通りの機能です。これらはカスタムリソースを定義する方法であり、本質的にはKubernetes APIを新しいオブジェクトで拡張するものです。
Kubernetesで Foo オブジェクトを作成/読み込み/更新/削除できるようにしたい場合、Foo リソースとは何か、どのように動作するのかを定義した CRD を作成します。そして、CRD のインスタンスである CustomResources (CRs) を作成することができます。
Operator の場合、一般的なパターンとしては、Operator が CRs を見て設定を行い、Kubernetes 環境上で operate を行い、設定で指定されたことを実行するというものです。ここでは、OpenShiftのインフラストラクチャオペレータのいくつかがどのように動作するかを見てみましょう。
インフラストラクチャコンポーネントの移動
これで Infra ノードができたので、インフラストラクチャのコンポーネントをその上に移動させることができます。
レジストリ
レジストリは、オペレータが実際のレジストリPodをどのように展開するかを設定するために、同様の CRD メカニズムを使用します。
このCRDは configs.imageregistry.operator.openshift.io です。
このCRDに nodeSelector を追加するために cluster のCRDオブジェクトを編集します。まず、それを見てみましょう。
oc get configs.imageregistry.operator.openshift.io/cluster -o yaml以下のように確認できます。
apiVersion: imageregistry.operator.openshift.io/v1
kind: Config
metadata:
creationTimestamp: "2019-08-06T13:57:22Z"
finalizers:
- imageregistry.operator.openshift.io/finalizer
generation: 2
name: cluster
resourceVersion: "13218"
selfLink: /apis/imageregistry.operator.openshift.io/v1/configs/cluster
uid: 1cb6272a-b852-11e9-9a54-02fdf1f6ca7a
spec:
defaultRoute: false
httpSecret: fff8bb0952d32e0aa56adf0ac6f6cf5267e0627f7b42e35c508050b5be426f8fd5e5108bea314f4291eeacc0b95a2ea9f842b54d7eb61522238f2a2dc471f131
logging: 2
managementState: Managed
proxy:
http: ""
https: ""
noProxy: ""
readOnly: false
replicas: 1
requests:
read:
maxInQueue: 0
maxRunning: 0
maxWaitInQueue: 0s
write:
maxInQueue: 0
maxRunning: 0
maxWaitInQueue: 0s
storage:
s3:
bucket: image-registry-us-east-2-0a598598fc1649d8b96ed91a902b982c-1cbd
encrypt: true
keyID: ""
region: us-east-2
regionEndpoint: ""
status:
...次のコマンドを実行します。image-registry-xxxxxxxxx-xxxxx が、レジストリを指す Pod でこの Pod をInfra ノードへ移動させます。
oc get pod -n openshift-image-registry -o wideそれでは、以下のコマンドによって、レジストリCRの .spec を修正し、nodeSelector を追加します。
oc patch configs.imageregistry.operator.openshift.io/cluster -p '{"spec":{"nodeSelector":{"node-role.kubernetes.io/infra": ""}}}' --type=merge
この時点では、イメージレジストリは演算子のために別のプロジェクトを使用していません。演算子とオペランドは両方とも openshift-image-registry プロジェクトの中にあります。
|
パッチコマンドを実行すると、レジストリPodがinfraノードに移動しているのがわかるはずです。
レジストリは openshift-image-registry プロジェクトにあります。
以下をく実行してみてください。
oc get pod -n openshift-image-registry -o wideレジストリはS3バケットによってバックアップされているので、新しいレジストリPodのインスタンスがどのノードにあるかは問題ではありません。 これはAPI経由でオブジェクトストアと通信しているので、そこに保存されている既存のイメージはすべてアクセス可能なままです。
また、デフォルトのレプリカ数は1であることにも注意してください。 現実の環境では、可用性やネットワークのスループットなどの理由から、このレプリカ数を増やしたいと思うかもしれません。
レジストリのPodが稼働しているノードを見てみると、それが現在infraワーカー上で実行されていることに気づくでしょう。
最後に、イメージレジストリの設定のための CRD が名前空間ではなく、クラスタスコープになっていることに注目してください。
OpenShiftクラスタごとに内部/統合レジストリは1つしかありません。