ワーカーノードの追加と削除
演習の概要
このモジュールでは、ワーカーノードの(自動的な)追加と削除を実施します。
MachineSetによるワーカーノードの追加と削除
実行するアプリケーションの数が多くなり、ワーカーノードのリソース(CPUやメモリ)使用率が逼迫した場合、 OpenShiftのコンソールからワーカーノードを追加・削除できます。 ARO/OpenShiftのワーカーノードは、MachineSetというリソース単位で管理されており、 ワーカーノードを追加・削除する場合、このMachineSetを作成・編集・削除します。
ここでインストラクターから案内された管理アカウントを使って、AROクラスターに再ログインします。 以降の演習は、この管理アカウントを利用します。
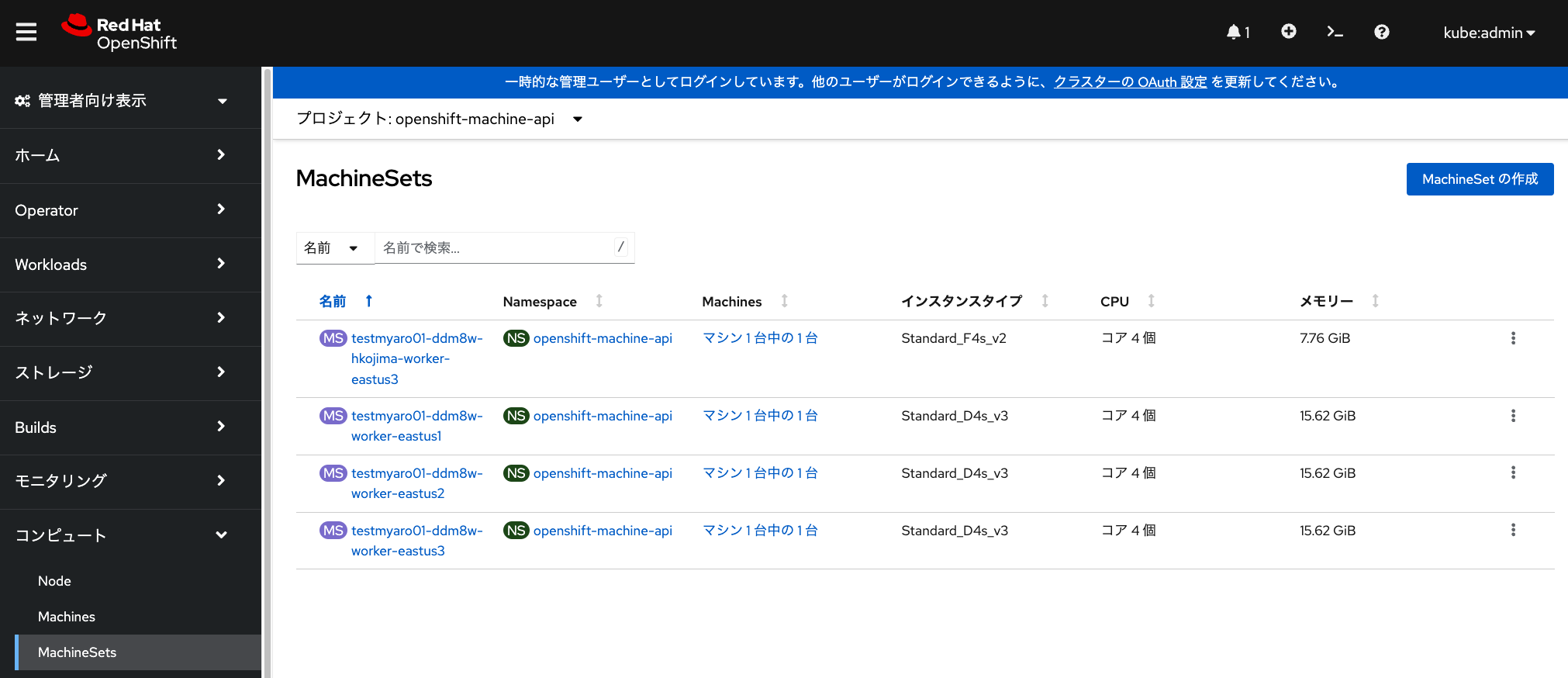
デフォルトで利用されているMachineSetは、 「管理者向け表示」の「MachineSets」メニューから確認できます。 Japan EastリージョンにあるAROを利用している場合、 デフォルトの構成では3つのアベイラビリティーゾーンに 対応したマシンセットが1つずつ存在します。 これらのマシンセットの中に1台ずつワーカーノードが含まれています。
| 本演習環境では、ワーカーノードを数台ほど増やしていることがあります。 |
| Azureの仕様により、Japan WestリージョンにあるAROの場合は、 1つのアベイラビリティーゾーンしか利用できないようになっています。 |
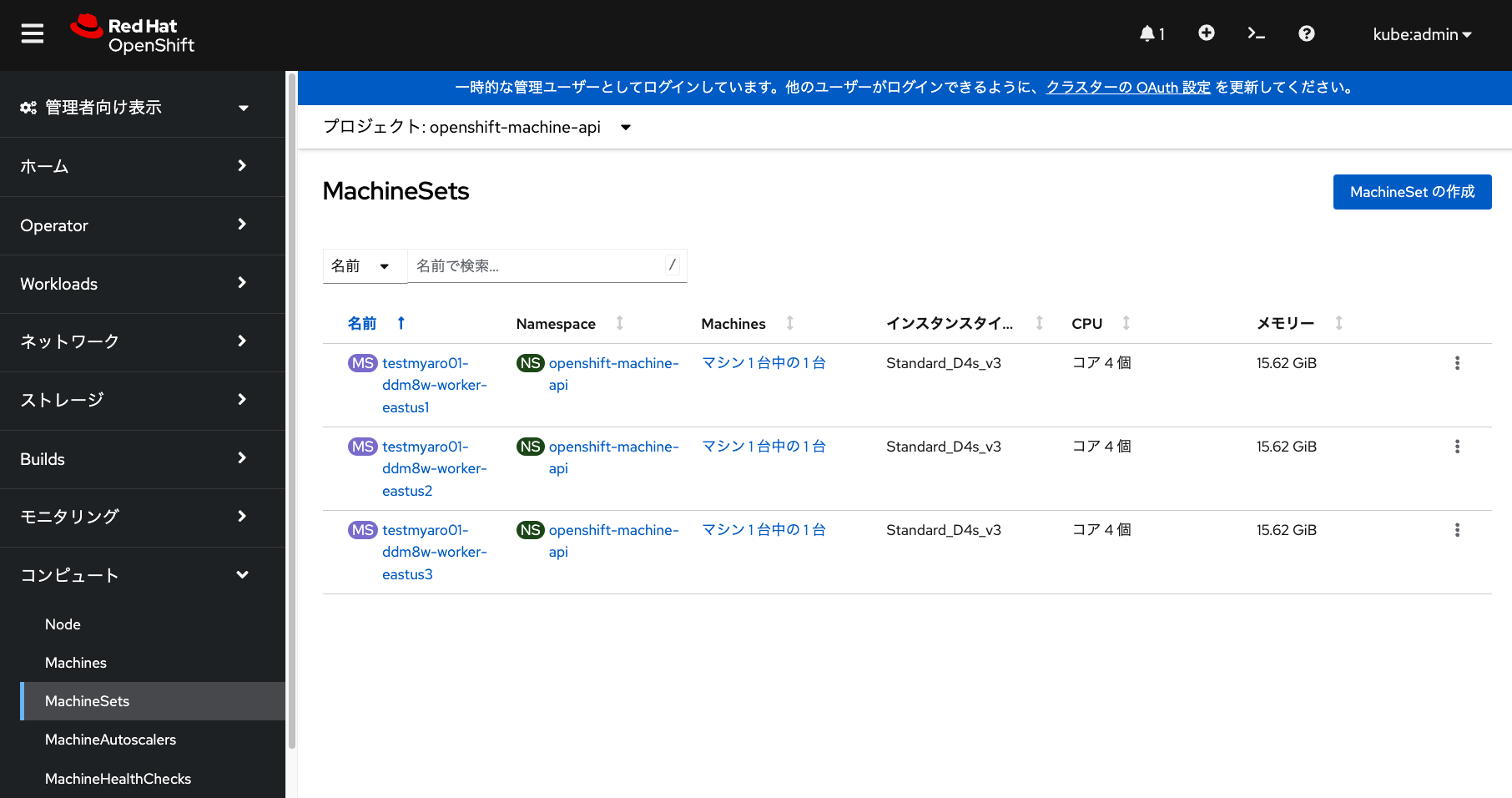
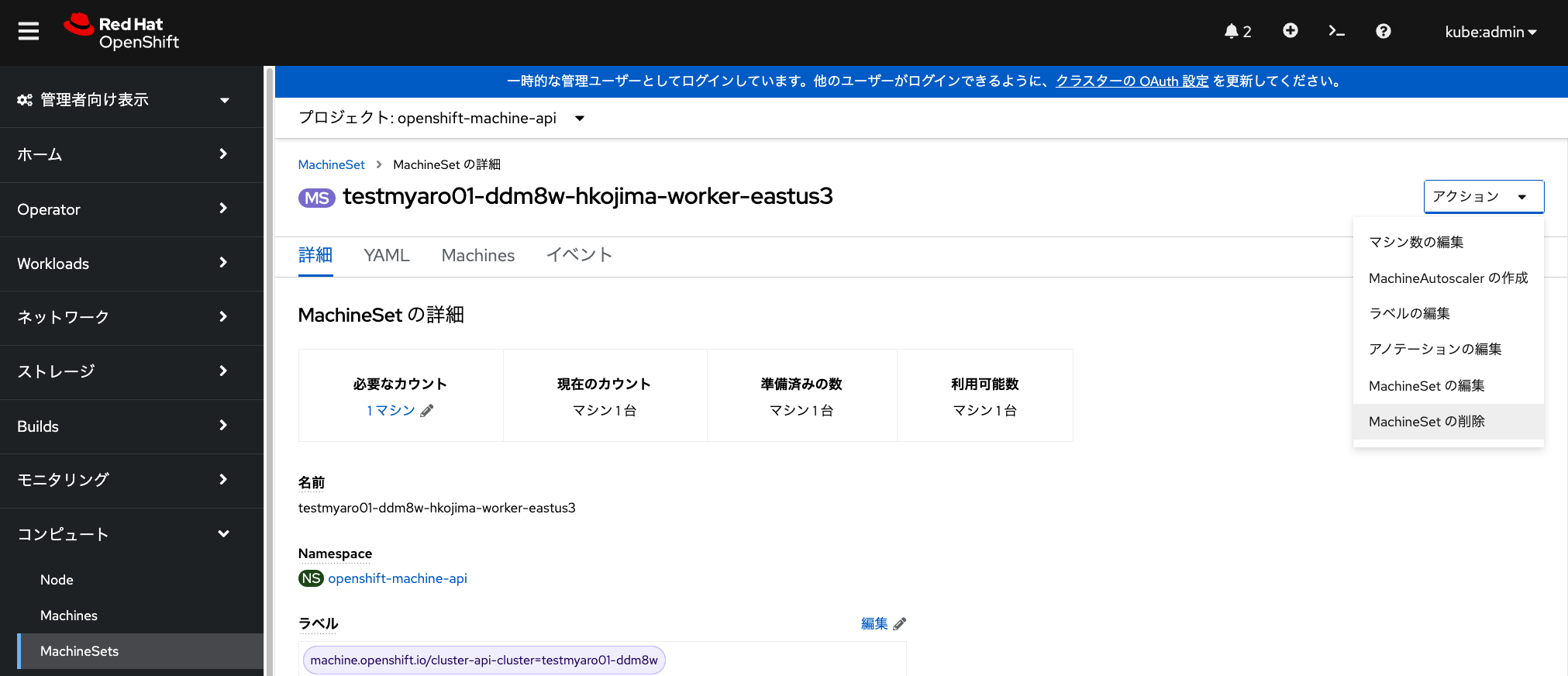
デフォルトで用意されているマシンセットのうち、いずれかを選択して、 「アクション」→「マシン数の編集」から、マシン台数を編集することで、 ワーカーノードを簡単に追加・削除できるようになっています。

しかし、この演習では、デフォルトで用意されているMachineSetは編集せずに、 新しくMachineSetを追加することで、ワーカーノードを追加してみます。
MachineSetの作成
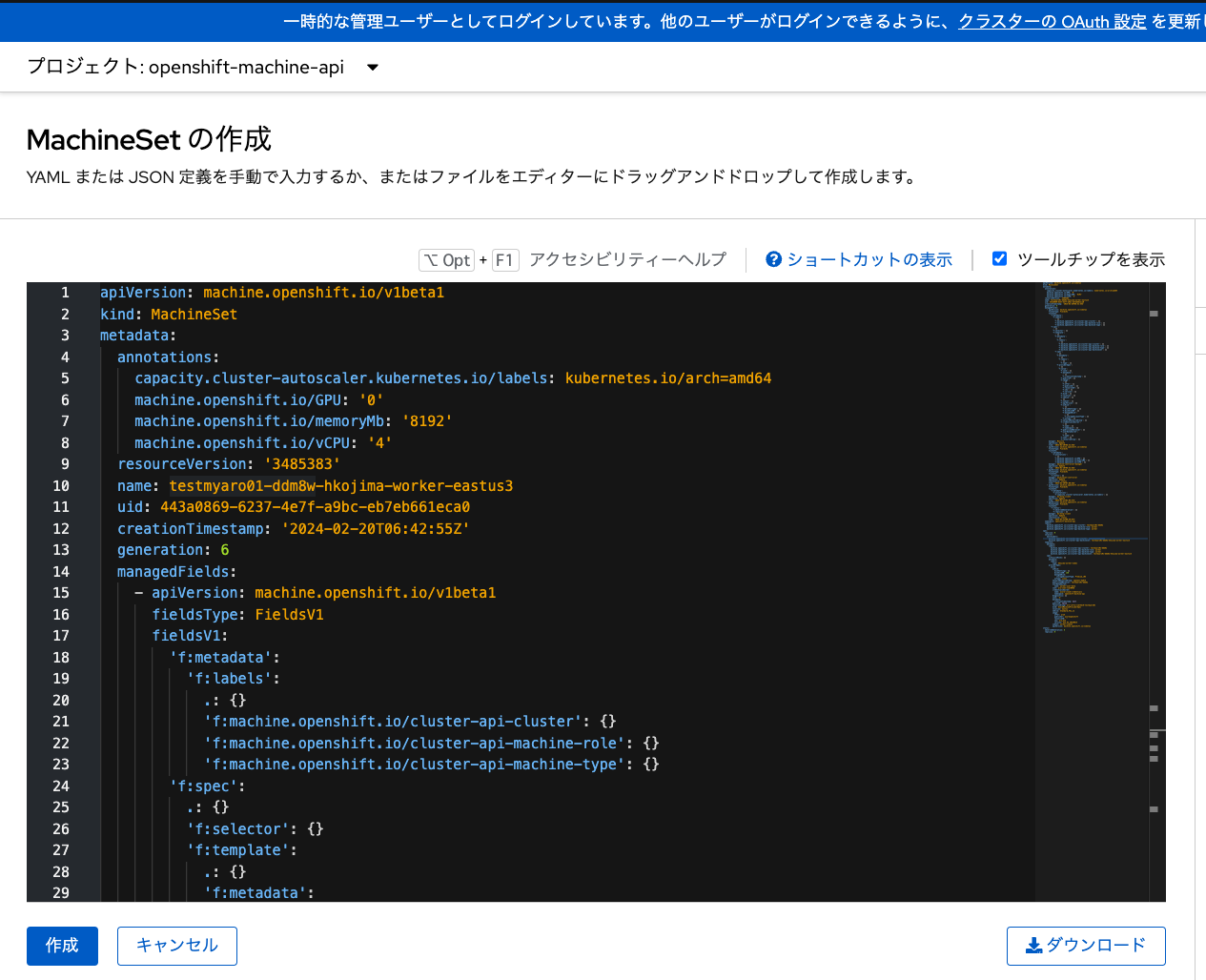
前述した画像にある「MachineSet」のメニューから「MachineSetの作成」をクリックして、
下記のようなMachineSetを定義したYAMLファイルを入力して、MachineSetを作成します。
新規MachineSetの作成に伴い、自動的にワーカーノードが1台( replicas: 1 の指定によるもの)
追加されます。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
name: <MachineSet名>
labels:
machine.openshift.io/cluster-api-cluster: <AROクラスター名>
machine.openshift.io/cluster-api-machine-role: worker
machine.openshift.io/cluster-api-machine-type: worker
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <AROクラスター名>
machine.openshift.io/cluster-api-machineset: <MachineSet名>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <AROクラスター名>
machine.openshift.io/cluster-api-machine-role: worker
machine.openshift.io/cluster-api-machine-type: worker
machine.openshift.io/cluster-api-machineset: <MachineSet名>
spec:
metadata:
labels:
<key>: <value>
providerSpec:
value:
location: <リージョン名>
networkResourceGroup: <ネットワークリソースグループ名>
publicLoadBalancer: <AROクラスター名>
resourceGroup: aro-<AROクラスターのインフラID>
vnet: <Virutal Network名>
subnet: <サブネット名>
vmSize: Standard_F4s_v2
zone: "3"
image:
offer: aro4
publisher: azureopenshift
resourceID: ""
sku: <AROのバージョンID>
version: <AROのバージョン番号が付いたイメージID>
apiVersion: machine.openshift.io/v1beta1
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
kind: AzureMachineProviderSpec
metadata:
creationTimestamp: null
userDataSecret:
name: worker-user-data
osDisk:
diskSettings: {}
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: falseMachineSetを新規作成する場合は、既存のMachineSetを参照しながら、値を変更すると便利です。
<> で囲んだところは、AROクラスターの環境に応じて適宜変更します。
具体的な変更内容については、当日インストラクターから案内されますが、
それぞれの変数の説明は次のとおりです。
-
MachineSet名: 任意に指定可能なMachineSet名。(例: testmyaro01-ddm8w-hkojima-worker-eastus3) -
AROクラスター名: マシンセットで参照されるAROクラスターの名前。(例: testmyaro01-ddm8w) -
key, value: マシンセットで指定する任意のラベル名。(例:「key」に「type」、「value」に「hkojima-worker-nodes」を指定。このラベルは後に使いますので、他の受講者と被らないようなラベルを付けて下さい) -
リージョン名: AROクラスターが作成されたリージョン名。(例: japaneast) -
ネットワークリソースグループ名: AROが利用するVirtual Networkリソースがあるリソースグループ名。(例: openenv-hkctf) -
AROクラスターのインフラID: AROクラスターに付けられたID。(例: myopendomain01) -
Virutal Network名: AROクラスターが利用するVirtual Network名。(例: myopenaro-vnet01) -
サブネット名: ワーカーノードが利用するサブネット名。(例: worker-subnet) -
AROのバージョンID: AROのバージョンのID。(例: aro_413) -
AROのバージョン番号が付いたイメージID: イメージID。(例: 413.92.20230614)
これらの変数を設定した、
MachineSetのサンプルファイルがありますので参考にしてください。
このサンプルでは、 vmSize: Standard_F4s_v2 でAROで利用可能な最小サイズのワーカーノードを指定し、
zone: “3” で3番目のアベイラビリティーゾーンを指定しています。
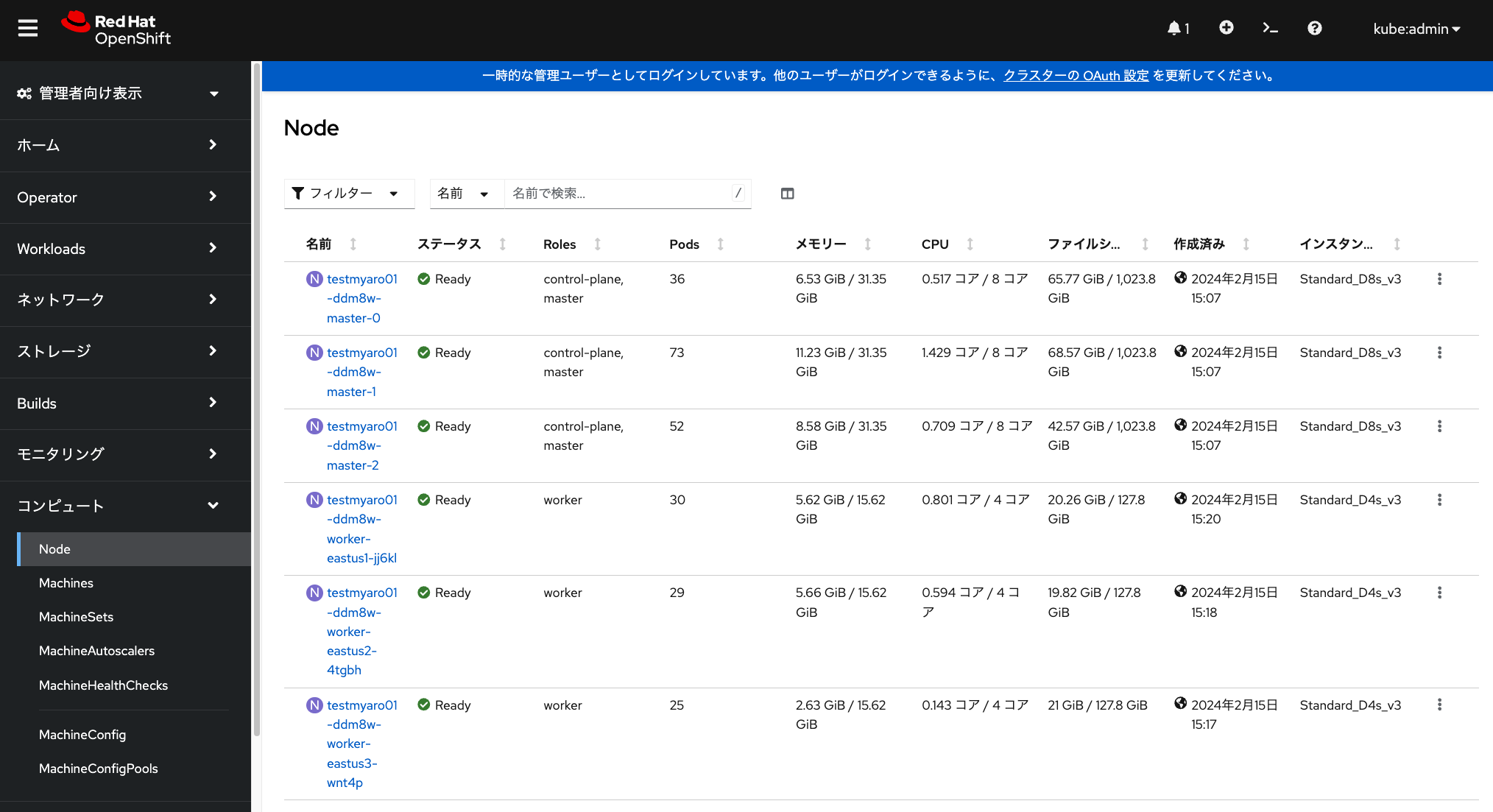
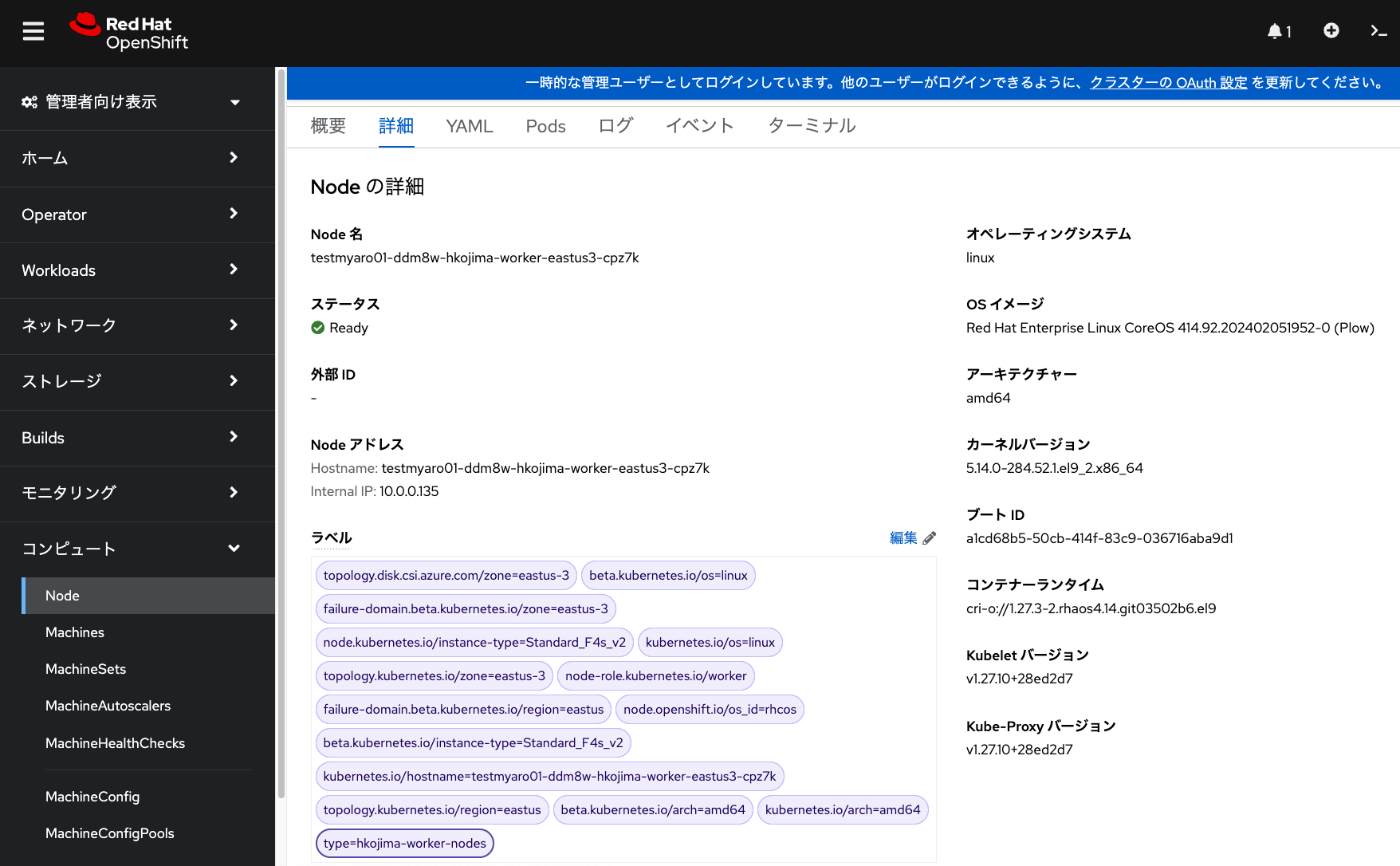
MachineSetの作成に伴い、対応したワーカーノードに、
前述したMachineSet作成時に指定したラベル(下記画像の例では、一番下のラベル type=hkojima-worker-nodes )が
自動的に付与されます。
このラベルを利用して、Podを特定のラベルが付いたワーカーノードで実行できるようになります。
オートスケールの設定
ARO/OpenShiftでのオートスケールを設定するには、次の2つの設定が必要になります。
-
Cluster Autoscaler: クラスター全体のオートスケールの設定。クラスター全体のコントローラおよびワーカーノードの上限値、CPU/メモリの最小/最大値などを設定 -
Machine Autoscaler: MachineSetに対するオートスケールの設定。最小台数と最大台数を設定
Cluster Autoscalerは、次のYAMLファイルを利用して、OpenShiftのWebコンソールから設定できます。
これはアラート設定手順の時と同様に、OpenShiftコンソールの右上にある + アイコンから
直接YAMLファイルを入力して作成します。Cluster Autoscalerの名前は、
default を指定する必要がありますので、注意してください。
| 本演習をワークショップ形式で実施している場合、Cluster Autoscalerはすでに設定されています。 |
apiVersion: "autoscaling.openshift.io/v1"
kind: "ClusterAutoscaler"
metadata:
name: "default"
spec:
podPriorityThreshold: -10
resourceLimits:
maxNodesTotal: 60
cores:
min: 8
max: 512
memory:
min: 4
max: 1024
scaleDown:
enabled: true
unneededTime: 6m
delayAfterAdd: 2m
delayAfterDelete: 1m
delayAfterFailure: 15sこの例では、最大60台までノードをデプロイ可能で、オートスケールダウンも設定し、 不要なノードが削除対象になるまでの時間を6分間と指定しています。 その他のパラメータの説明については、 OpenShiftの製品ドキュメントもご参照ください。
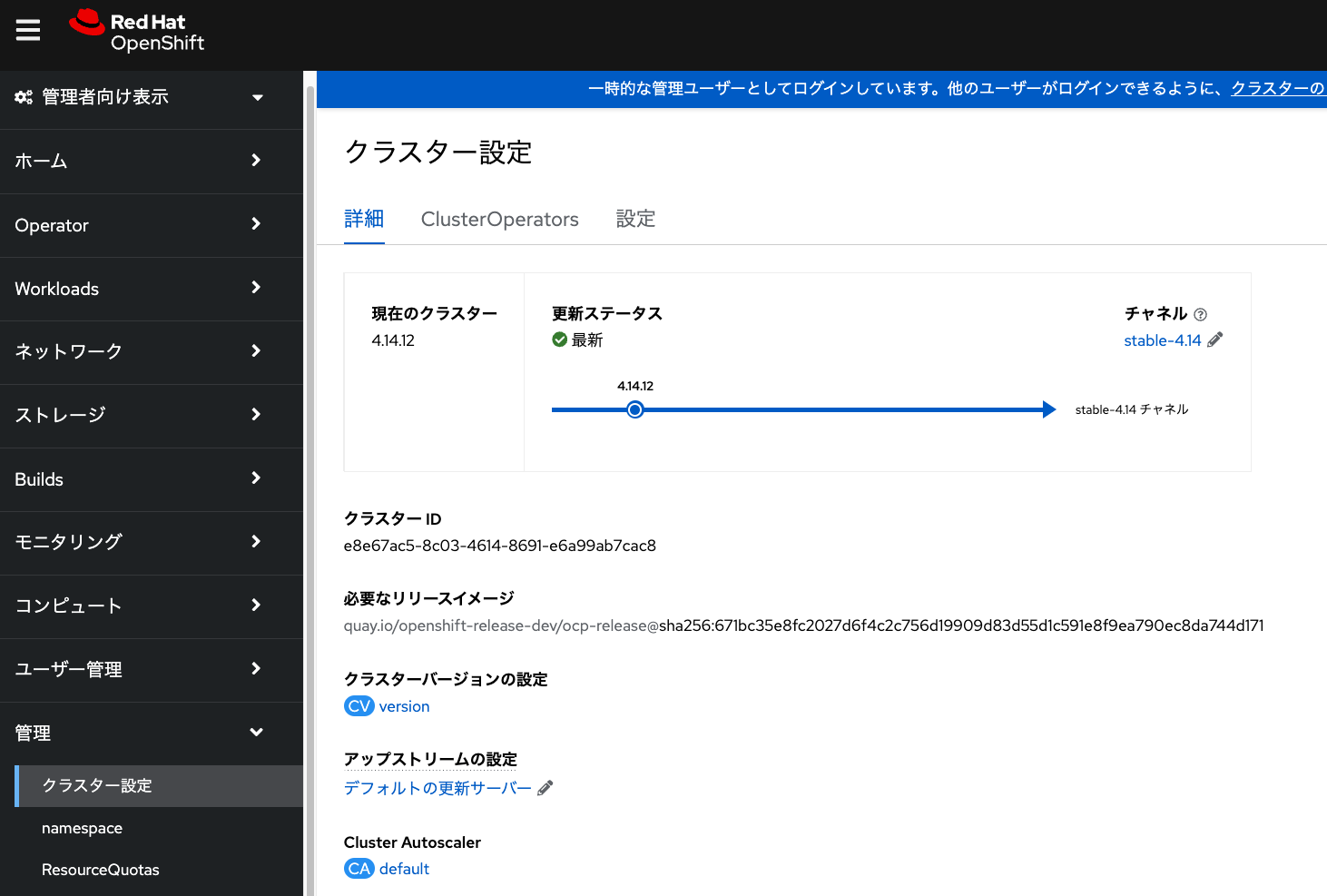
Cluster Autoscalerが作成されると、下記の画像の一番下に default という名前で
作成されていることが確認できます。
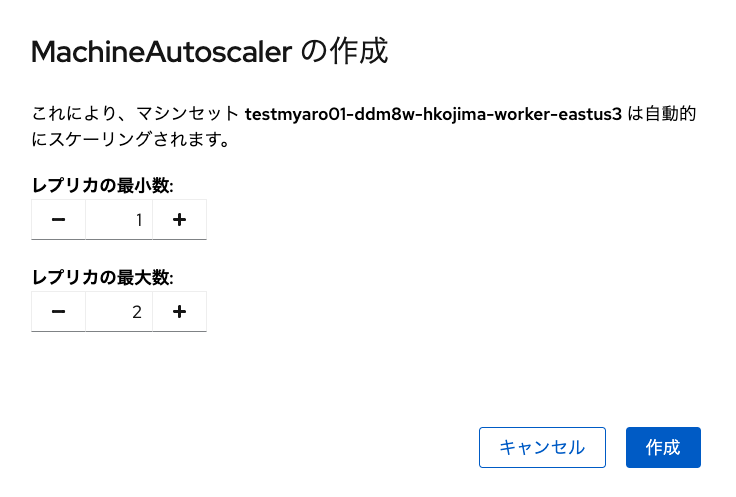
続いて、Machine Autoscalerの設定です。これは前述した手順で 受講者が作成したMachineSetの右側にある「・」が縦に3つ並んだアイコンをクリックして、 「Machine Autoscalerの作成」をクリックし、最小数と最大数を設定するだけの手順です。 今回の演習では、最小数を「1」、最大数を「2」と設定してください。
オートスケールのテスト
実際にオートスケールをテストしてみます。
受講生が作成したプロジェクトを適宜指定して、
次のYAMLファイルで、busybox Podを15個並列に実行するジョブを実行します。
このジョブも、OpenShiftコンソールの右上にある + アイコンから直接入力して作成します。
このとき、先ほどMachineSetを作成する時に指定したラベルを利用して、
このジョブによって作成されるPodが、受講者が作成したMachineSet内だけで実行されるように、
「nodeSelector」を指定します。
ラベルの「key: value」の「value」に相当する文字列(この例では、 <ユーザー名>-worker-nodes )は、
ダブルクォーテーションで囲む必要があります。
これを忘れると、「value」の値が文字列として認識されないため、
ラベルの指定ができず、CPU/メモリのリソースが空いている任意のワーカーノードで
Podが実行されるようになるため、注意してください。
apiVersion: batch/v1
kind: Job
metadata:
generateName: work-queue-
spec:
template:
spec:
nodeSelector:
type: "<ユーザー名>-worker-nodes"
containers:
- name: work
image: busybox
command: ["sleep", "360"]
resources:
requests:
memory: 500Mi
cpu: 500m
restartPolicy: Never
backoffLimit: 4
completions: 15
parallelism: 15ジョブを実行して数分待つと、MachineSet Autoscalerを設定したMachineSetによって、 自動的にワーカーノードが1台追加され、追加されたワーカーノード上でPodが実行されることを確認できます。 これらは「Jobs」メニューや、「コンピュート」の中にある「Node」や「MachineSet」といったメニューを見ることで確認できます。
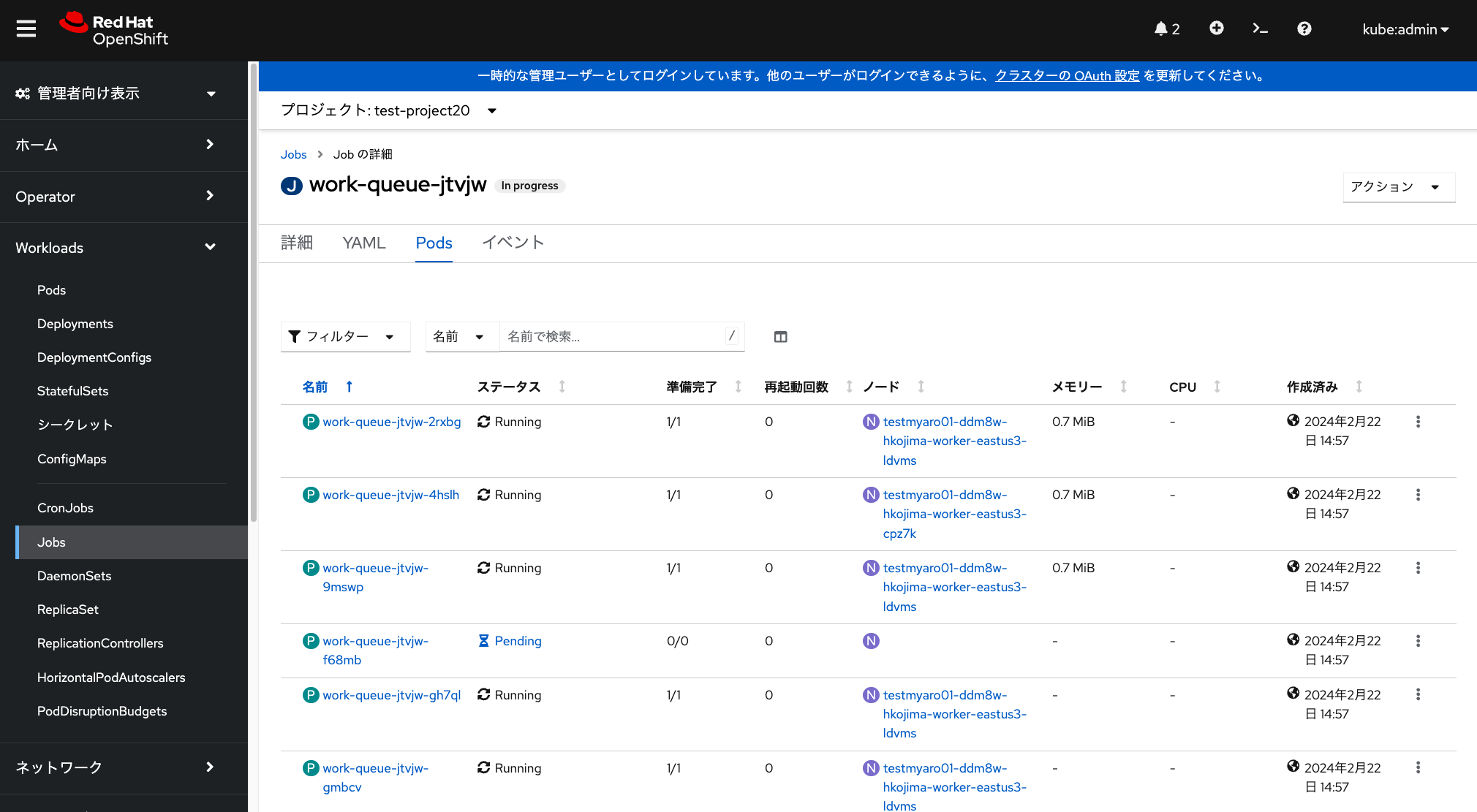
この演習環境の場合、ジョブ実行が完了し、不要になったワーカーノード1台が オートスケールダウンによって削除されるまで、20分ほどかかります。 途中でジョブの実行を中止したい場合、当該ジョブを選択して、 右上の「アクション」メニューから、「Jobの削除」を選択して「削除」を選択します。 これによりジョブによって起動されたPodが全て削除され、数分経つと、自動的にワーカーノードが1台削除されます。
最後に受講生が作成したMachineSetを削除します。 当該MachineSetを選択して、「MachineSetの削除」を選択することで、 MachineSet及びそれに紐づく全てのワーカーノードが削除されます。