ワーカーノードの追加と削除
演習の概要
このモジュールでは、ワーカーノードの(自動的な)追加と削除を実施します。
ワーカーノードの追加と削除
実行するアプリケーションの数が多くなり、ワーカーノードのリソース(CPUやメモリ)使用率が逼迫した場合、 ROSA CLI(rosaコマンド)を使用して、ワーカーノードを簡単に追加・削除できます。 ROSAのワーカーノードは、Machinepoolというリソース単位で管理されており、 ワーカーノードを追加・削除する場合、このMachinepoolを作成・編集・削除します。
デフォルトで利用されているMachinepoolは、 rosa list machinepool コマンドで確認します。
本演習をワークショップ形式で実施している場合、 -c オプションで指定するROSAクラスター名は、
rosa list cluster コマンドで表示される名前を指定してください。
複数のクラスターがある場合は、各受講者にどのクラスターを使うべきかをご案内します。
以下の手順は、 hcp-01 という名前のROSAクラスターを例とします。
|
$ rosa list cluster
ID NAME STATE TOPOLOGY
280scqkn8ocjoochasq423tg4donvpaq hcp-01 ready Hosted CP
$ rosa list machinepool -c hcp-01
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR
workers No 2/2 m5.xlarge us-east-2a subnet-0087cb7bb3f628793 4.14.2 Yes上記の例では、ワーカーノードに対応したAWS EC2インスタンス(デフォルトはm5.xlarge)を2台起動しているという設定を確認できます。
| このコマンドの出力結果は、利用しているROSA HCPクラスターによって変わることがあります。 |
ここにmachinepoolを新しく作成して、ワーカーノードを1台追加します。 rosa create machinepool コマンドを実行します。
| 1つのROSAクラスターを受講生で共有している場合、他の受講生と重複しないMachinepoolの名前を付けて下さい。 |
$ rosa create machinepool -c hcp-01
I: Enabling interactive mode
? Machine pool name: mp20
? OpenShift version: [Use arrows to move, type to filter, ? for more help]
> 4.14.2
4.14.1
4.14.0
? OpenShift version: 4.14.2
? Select subnet for a hosted machine pool: Yes
? Subnet ID: subnet-0087cb7bb3f628793 ('hcp-cluster01-vpc-private-use2-az1','vpc-0727149c80d7f166f','us-east-2a', Owner ID: '999417968296')
? Enable autoscaling: No
? Replicas: 1
? Labels (optional):
? Taints (optional):
I: Fetching instance types
? Instance type: m5.xlarge
? Autorepair: Yes
I: Machine pool 'mp20' created successfully on hosted cluster 'hcp-01'
I: To view all machine pools, run 'rosa list machinepools -c hcp-01'ROSA HCPクラスターでは、コントロールプレーンより古いバージョンのワーカーノードをデプロイできます。
上記の例では、 4.14.2 を選択していますが、他の古いバージョンも選択できます。
Subnet IDで、ROSA HCPクラスター作成時に指定した、AWS VPCのプライベートサブネットIDを指定します。 ROSA HCPクラスターでは、AZにあるサブネットIDを指定して、 SingleAZ構成/MultiAZ構成の両方で、ワーカーノードを最低1台から、AZ単位で追加できるようになっています。
Replicasで、作成するワーカーノードの台数(ここでは1台)を指定します。 Autorepairは、ワーカーノードの反応が無くなったとき、新規作成したワーカーノードに置換することを意味します。
| 2023年12月時点では、ROSA HCPクラスターではEC2スポットインスタンスの利用はできません。 |
再度 rosa list machinepool コマンドを実行して、machinepool mp20 が正常に作成されたかを確認します。
ワーカーノードに紐づいたEC2インスタンスの作成完了まで、5~10分ほどかかります。
$ rosa list machinepool -c hcp-01
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR
mp20 No 1/1 m5.xlarge us-east-2a subnet-0087cb7bb3f628793 4.14.2 Yes
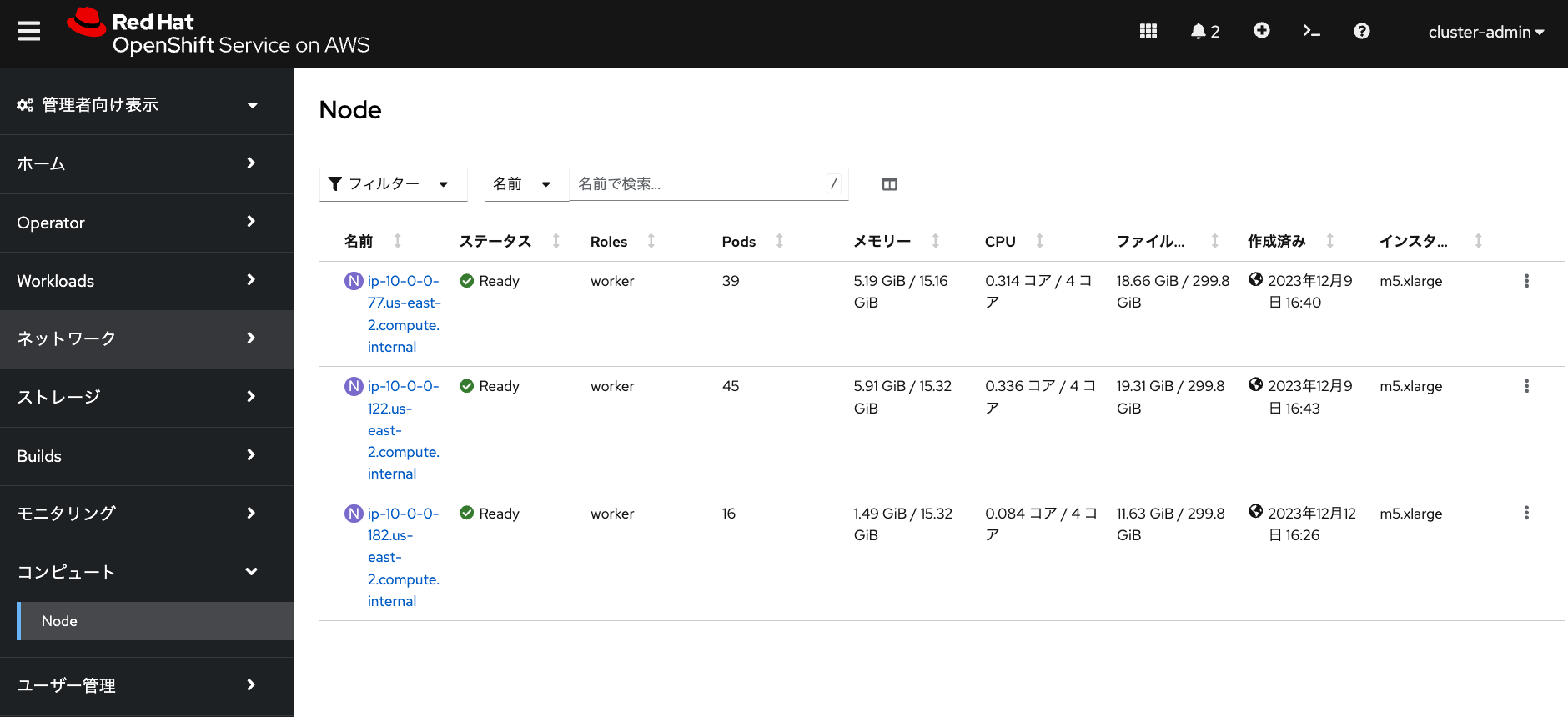
workers No 2/2 m5.xlarge us-east-2a subnet-0087cb7bb3f628793 4.14.2 YesROSAクラスターに管理者アカウント( cluster-admin など)でログインしてみると、
「コンピュート」→「Node」メニューから「作成済み」の日時を見ることで、ワーカーノードが新しく作成されていることがわかります。
mp20 に紐づけられているワーカーノードの台数を修正したい場合、rosa edit machinepool コマンドを実行します。
下記では、 replicas 0 を指定して、ワーカーノードの台数を0台にしています。
ROSAクラスターの「Node」メニューから、 mp20 に対応したワーカーノード1台が削除されていることを確認できます。
$ rosa edit machinepool mp20 -c hcp-01 --replicas 0
I: Updated machine pool 'mp20' on cluster 'hcp-01'
$ rosa list machinepool -c hcp-01
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR
mp20 No 0/0 m5.xlarge us-east-2a subnet-0087cb7bb3f628793 4.14.2 Yes
workers No 2/2 m5.xlarge us-east-2a subnet-0087cb7bb3f628793 4.14.2 Yesオートスケールの設定
Machinepoolは、作成時または作成後にオートスケールの設定をすることができます。 オートスケールが有効化されていると、利用者がPodをデプロイしようとした時に、リソース(CPUやメモリ)の使用量が逼迫していて、 どのワーカーノードにもデプロイできないPodがある場合、自動的にワーカーノードを追加します。
また、その逆に、一部のノードが一定期間にわたって、リソースがあまり使われていない状態が続く場合、 ワーカーノードを削除してROSAクラスターのサイズを縮小します。
上記で作成した mp20 のオートスケールの設定変更は、 rosa edit machinepool コマンドで実行します。
次のコマンドでは、最小1台、最大2台のオートスケールの設定の有効化と無効化をしています。
$ :↓ オートスケールの有効化
$ rosa edit machinepool mp20 -c hcp-01 --enable-autoscaling=true
? Min replicas: 1
? Max replicas: 2
I: Updated machine pool 'mp20' on hosted cluster 'hcp-01'
$ :↓ オートスケールの無効化
$ rosa edit machinepool mp20 -c hcp-01 --enable-autoscaling=false
? Replicas: 1
I: Updated machine pool 'mp20' on hosted cluster 'hcp-01'Machinepoolの設定・作成・削除は、 OpenShift Cluster Manager (OCM)からも実施できます。 オートスケールの設定の場合だと、「Enable autoscaling」のチェックボックスによって、 オートスケールの有効化/無効化ができます。
| 本演習をワークショップ形式で実施している場合、OCMにはアクセスできません。 |
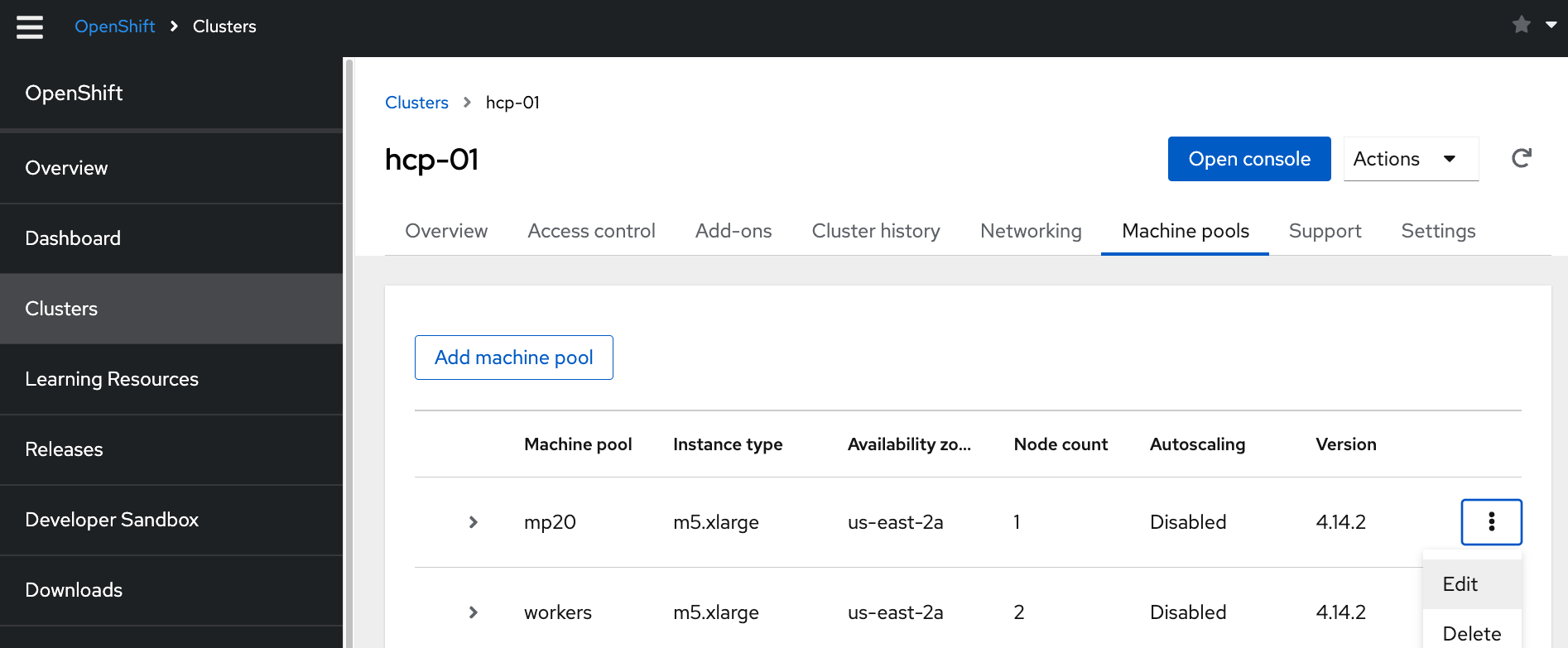
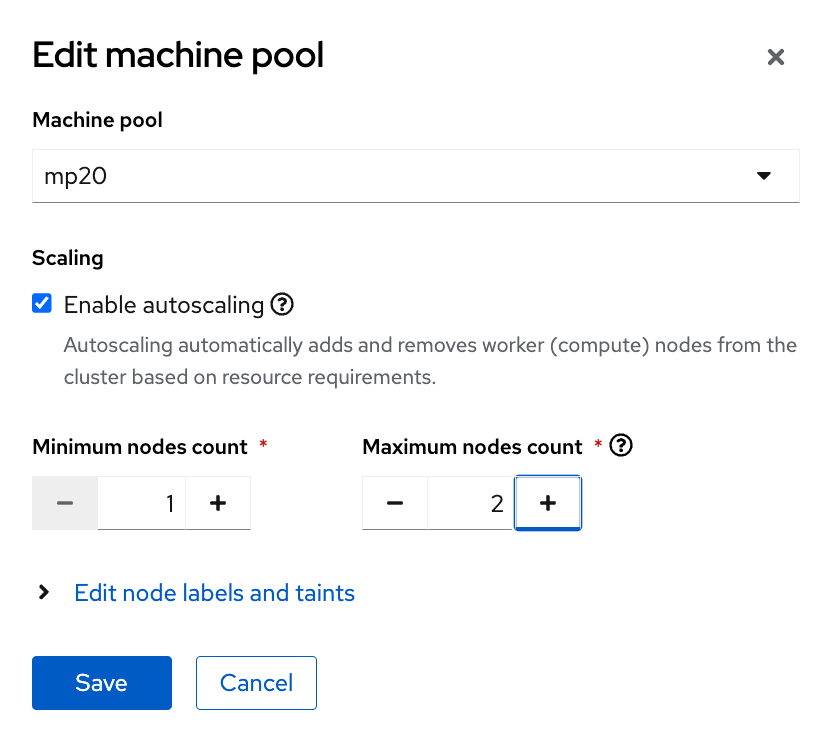
作成したMachinepoolを削除する場合、
rosa delete machinepool コマンドを実行します。
これによってワーカーノードが削除され、その上で実行されているPodも削除されます。
次の「オートスケールの確認」演習を実施する場合、 rosa delete machinepool コマンドはまだ実行しないで下さい。
|
$ rosa delete machinepool mp20 -c hcp-01
? Are you sure you want to delete machine pool 'mp20' on hosted cluster 'hcp-01'? Yes
I: Successfully deleted machine pool 'mp20' from hosted cluster 'hcp-01'オートスケールの確認
オートスケールが正常に動作するかを実際に確認してみます。 Machinepoolを作成した時に、それに紐づいたワーカーノードに自動的に付与されるラベルを利用して、 ワーカーノードの台数の増減を確認します。
前の手順で作成したMachinepoolに対して、再度オートスケールを有効化します。
$ rosa edit machinepool mp20 -c hcp-01 --enable-autoscaling=true
? Min replicas: 1
? Max replicas: 2
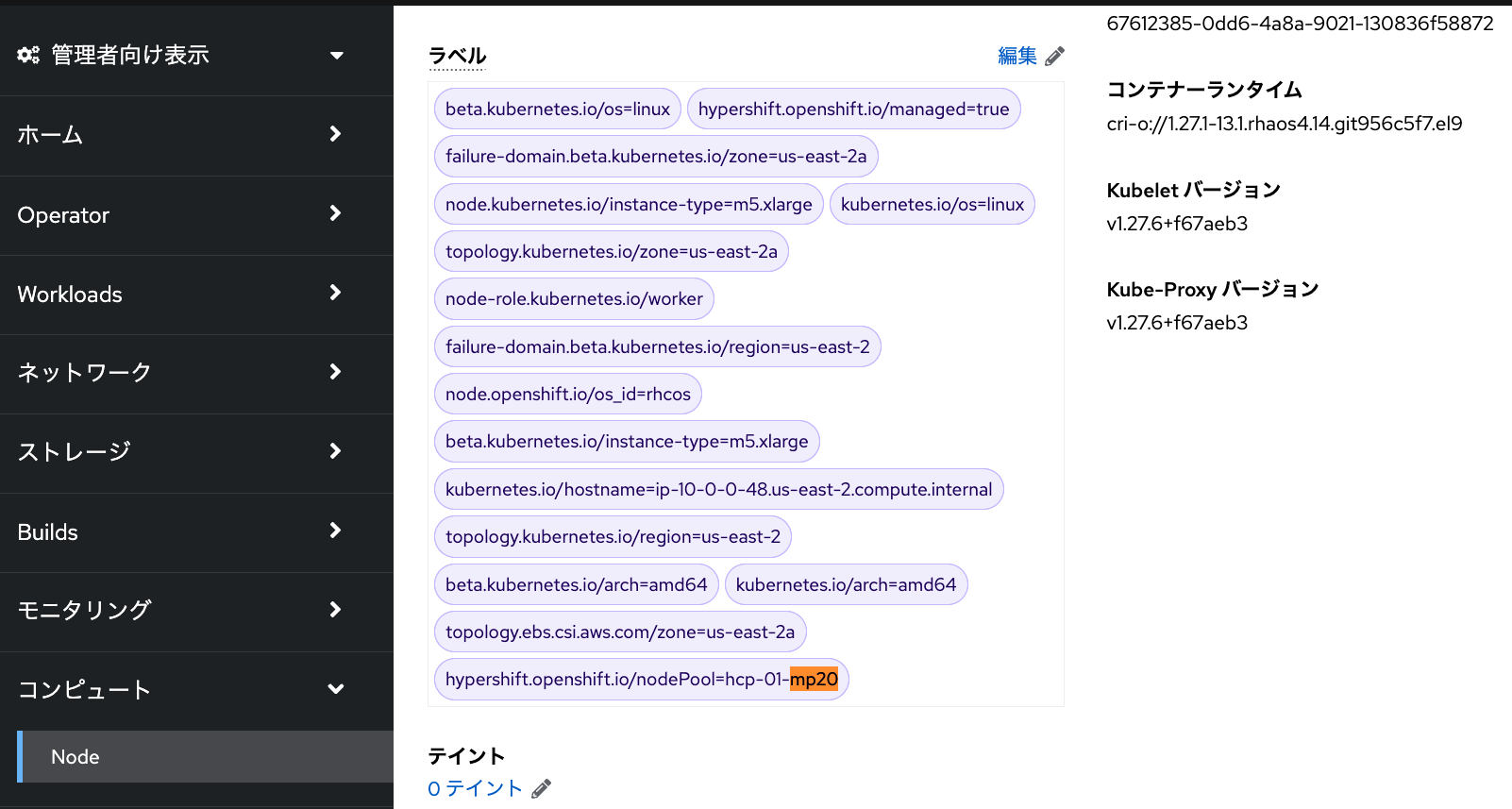
I: Updated machine pool 'mp20' on hosted cluster 'hcp-01'Machinepoolに紐づくワーカーノードに自動付与されるラベルのうち、ROSAクラスターのコンソールの
「コンピュート」→「Node」メニューから当該ノードを選択して、「詳細」タブの「ラベル」に表示されている
hypershift.openshift.io/nodePool=<ROSAクラスター名>-<Machinepool名> を使います。
下記の画像の例では、 hypershift.openshift.io/nodePool=hcp-01-mp20 というラベルが、
ワーカーノードに付与されています。
rosa create machinepool コマンドでMachinepoolを作成する時に、
labels=key1=value1,key2=value2,… 形式のオプションを指定することで、任意のラベルを付与できます。
「key」と「value」については、任意の文字列を指定できます。
2023年12月時点では、 rosa edit machinepool コマンドでMachinepoolを編集する際にラベルを付与しても、
Machinepoolに紐づいたワーカーノードにラベルが付与されないというバグがありますので、ご注意ください。
|
ここで、実際にサンプルジョブを投入して確認してみましょう。
次のYAMLファイルで busybox Podを15個並列に実行するジョブを投入します。
このとき、先ほど確認したラベルを利用して、
このジョブによって作成されるPodが、受講者が作成したMachinepool内だけで実行されるように、
「nodeSelector」を指定します。
ラベルの「key: value」の「value」に相当する文字列(この例では、hcp-01-mp20 )は、
ダブルクォーテーションで囲む必要があります。
これを忘れると、「value」の値が文字列として認識されないため、ラベルの指定ができず、
CPU/メモリのリソースが空いている任意のワーカーノードでPodが実行されるようになるため、注意してください。
apiVersion: batch/v1
kind: Job
metadata:
generateName: work-queue-
spec:
template:
spec:
nodeSelector:
hypershift.openshift.io/nodePool: "hcp-01-mp20"
containers:
- name: work
image: busybox
command: ["sleep", "360"]
resources:
requests:
memory: 500Mi
cpu: 500m
restartPolicy: Never
backoffLimit: 4
completions: 15
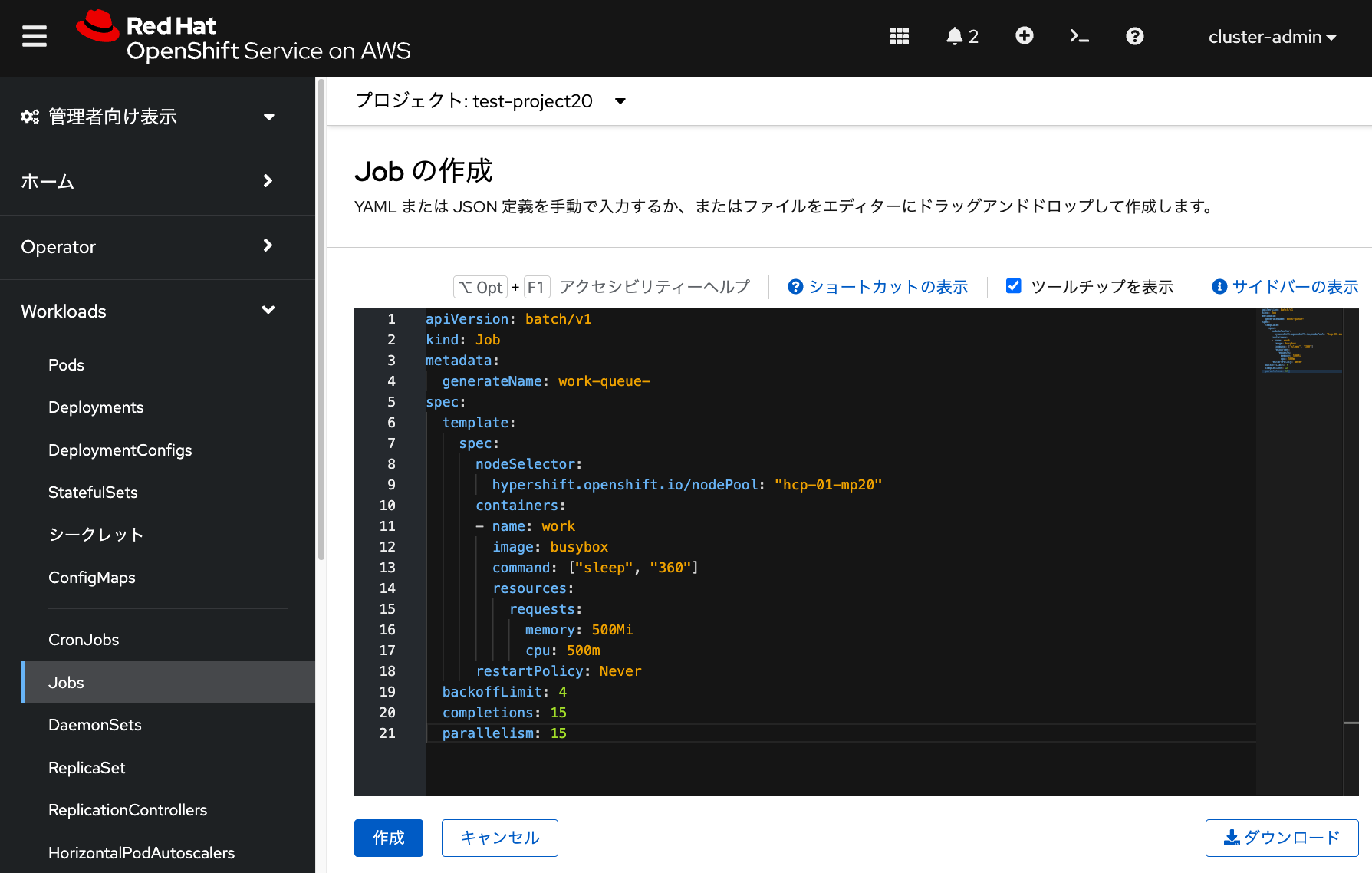
parallelism: 15OpenShiftでのジョブは、「ワークロード」メニューの「ジョブ」から「Jobの作成」をクリックして、 上記YAMLファイルをコピペして「作成」をクリックすることで作成できます。
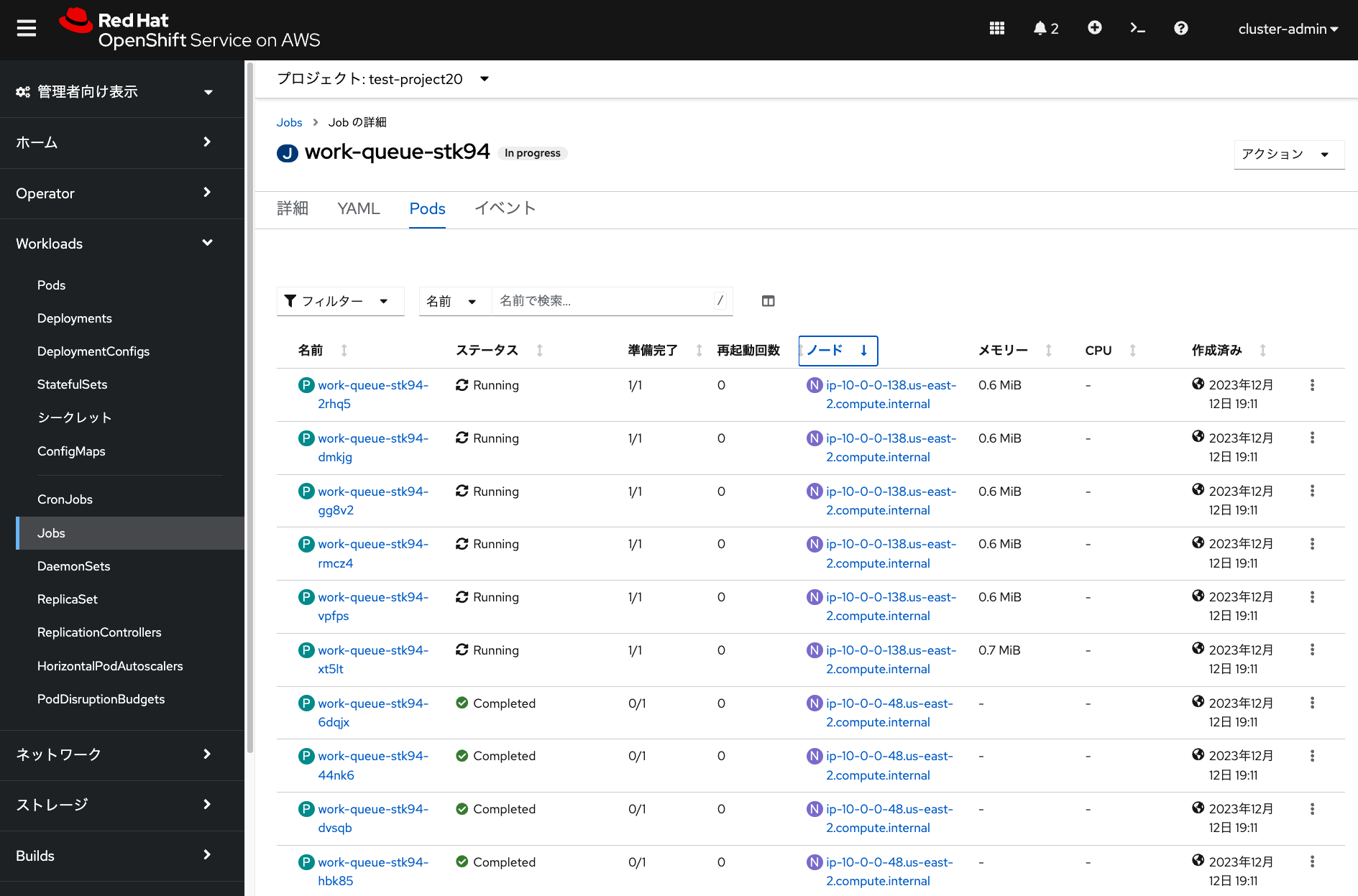
ジョブを実行して数分待つと、ジョブの「Pod」から次のような実行状況の画面を確認できます。 この画像の例では、最初にワーカーノード「ip-10-0-0-48.XXX」で 一部のPodがジョブによって実行され、Machinepoolのオートスケールの設定により、 ワーカーノード「ip-10-0-0-138.XXX」が自動的に追加され、 ジョブのPodを並列に実行していっていることを示しています。
この他にも、管理者アカウントでログインしたROSAクラスターのコンソールの「コンピュート」→「Node」メニューから、 自動的にワーカーノードが追加されている状況を確認できます。
前述のコマンドで作成したm5.xlargeインスタンスのMachinepoolを利用して、 このオートスケールのテストを実行した場合、所要時間の内訳は下記となり、合計で大体25分ほどかかります。
-
ジョブの実行開始から完了まで: 15分ほど
-
ジョブの実行完了から、追加されたワーカーノード1台の自動削除が完了するまで: 10分ほど
途中でジョブの実行を中止したい場合、 当該ジョブの「Jobの削除」を選択して「削除」をクリックすることで、ジョブを削除できます。 これにより、ジョブによって起動されたPodが全て削除され、 10分ほど経つと、追加されたワーカーノード1台が自動的に削除されます。
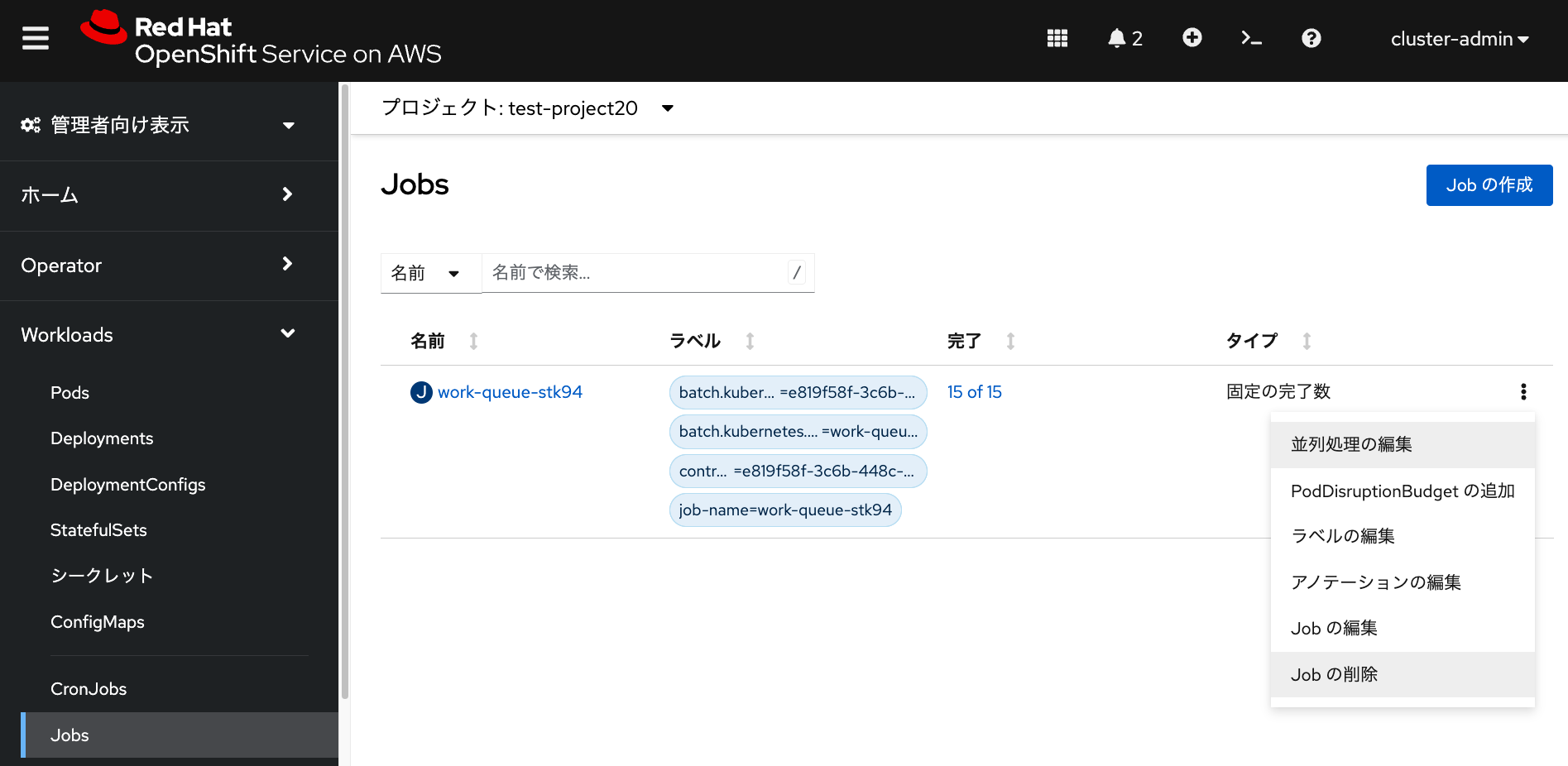
最後に、受講者が作成したMachinepoolを、 rosa delete machinepool コマンドで削除します。
$ rosa delete machinepool mp20 -c hcp-01
? Are you sure you want to delete machine pool 'mp20' on hosted cluster 'hcp-01'? Yes
I: Successfully deleted machine pool 'mp20' from hosted cluster 'hcp-01'