実環境でのスケーリングシナリオ
このラボモジュールでは、世界中の多くの仮想化管理者が日常的に遭遇するシナリオを段階的に実行します。 システムに高いレベルの負荷をかけ、最初のモジュールで探求した管理ツールを使用して、リソースの垂直スケーリングと水平スケーリングを含むさまざまな方法で状況を評価し、修正します。
モジュールセットアップ
このラボのパートでは、Red Hat OpenShift 環境の windows-vms プロジェクトで loadmaker アプリケーションがまだ実行されていることを確認する必要があります。
-
左側のナビゲーションメニューを使用して Workloads、次に Deployments をクリックします。
-
プロジェクト: windows-vms にいることを確認してください。
-
ここにデプロイされた Pod が 1 つ表示されるはずです。これは loadmaker と呼ばれます。
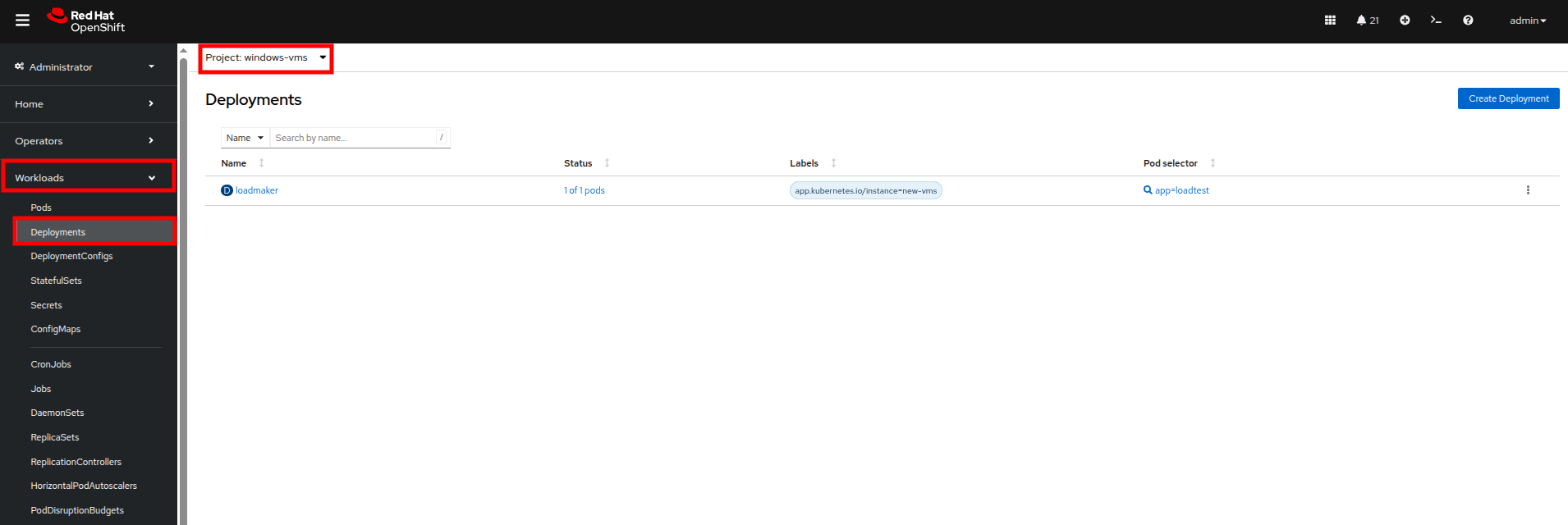 Figure 1. Loadmaker Deployment
Figure 1. Loadmaker Deployment -
loadmaker をクリックすると、Deployment details ページが表示されます。
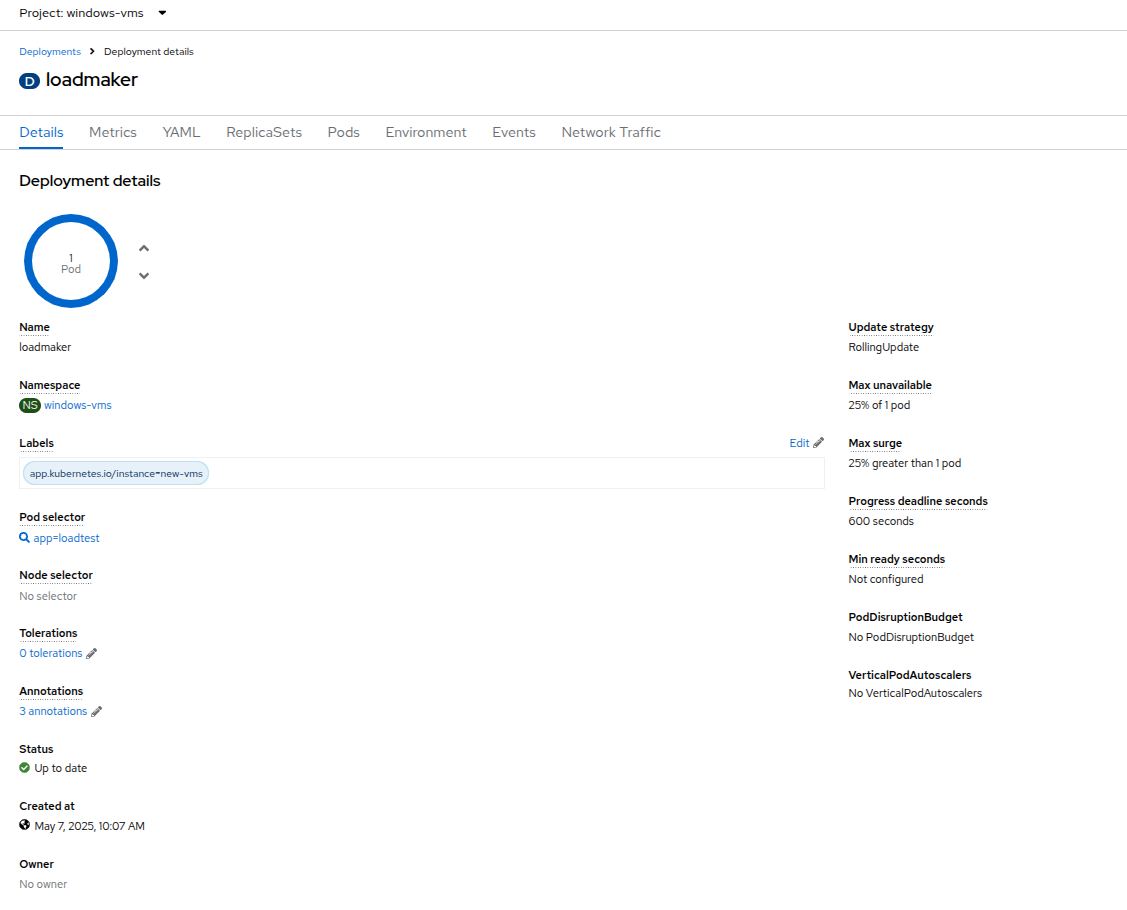 Figure 2. Deployment Details
Figure 2. Deployment Details -
Environment をクリックすると、REQUESTS_PER_SECOND のフィールドが表示されます。まだ設定されていない場合は、値を
75に変更し、下部の Save ボタンをクリックします。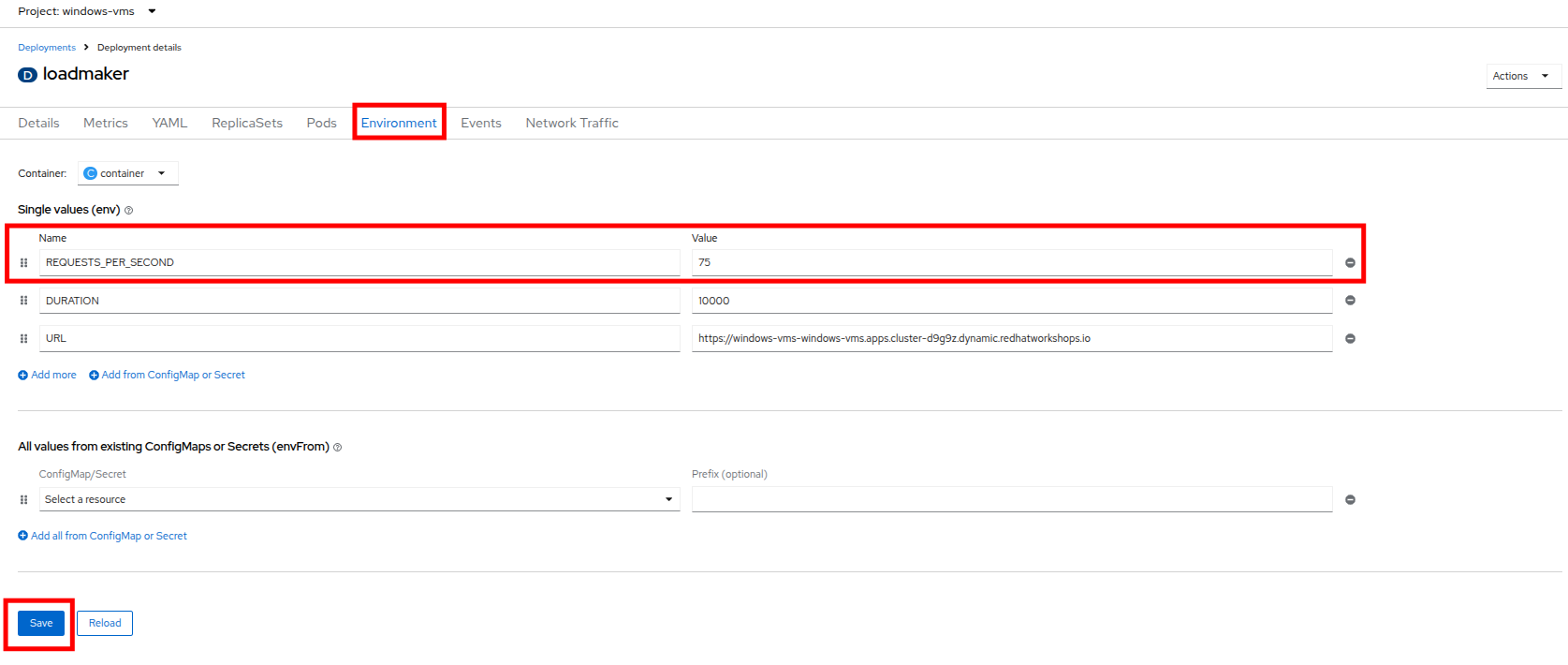 Figure 3. LM Pod Config
Figure 3. LM Pod Config -
さて、負荷を生成している VM を確認しに行きましょう。
-
左側のナビゲーションメニューで Virtualization、次に VirtualMachines をクリックします。中央の列で windows-vms プロジェクトを選択します。 3 つの仮想マシンが表示されるはずです: winweb01、winweb02、および database。
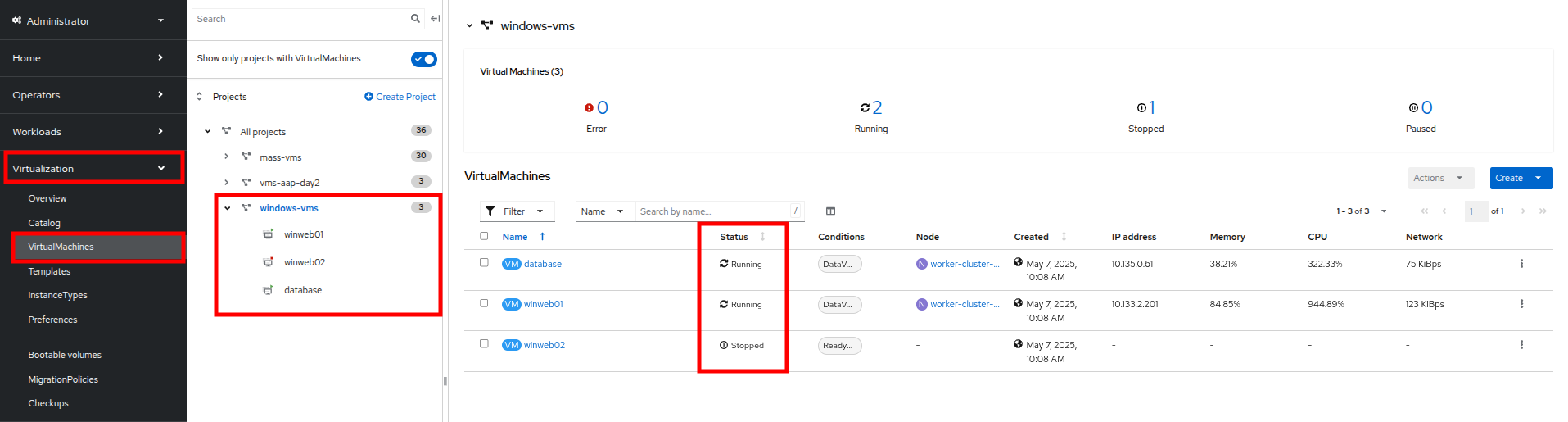 Figure 4. Windows VMs
Figure 4. Windows VMs重要: このラボの時点では、database と winweb01 のみが電源オンになっているはずです。 もしオフになっている場合は、今すぐ電源をオンにしてください。winweb02 は当面電源をオンにしないでください。
仮想マシンのリソース使用率の確認
winweb01、winweb02、および database サーバーは連携して、2 台の Web サーバー間で Web リクエストをロードバランスすることで、負荷を軽減し、パフォーマンスを向上させるシンプルな Web ベースのアプリケーションを提供します。 現時点では、Web サーバーは 1 台のみ稼働しており、高い需要にさらされています。 このラボのセクションでは、Web サーバーを水平スケーリングすることが、VM の負荷を軽減するのにどのように役立つか、また OpenShift Virtualization にネイティブなメトリックとグラフを使用してこれを診断する方法を見ていきます。
-
現在実行中であるはずの winweb01 をクリックします。これにより VirtualMachine details ページが表示されます。
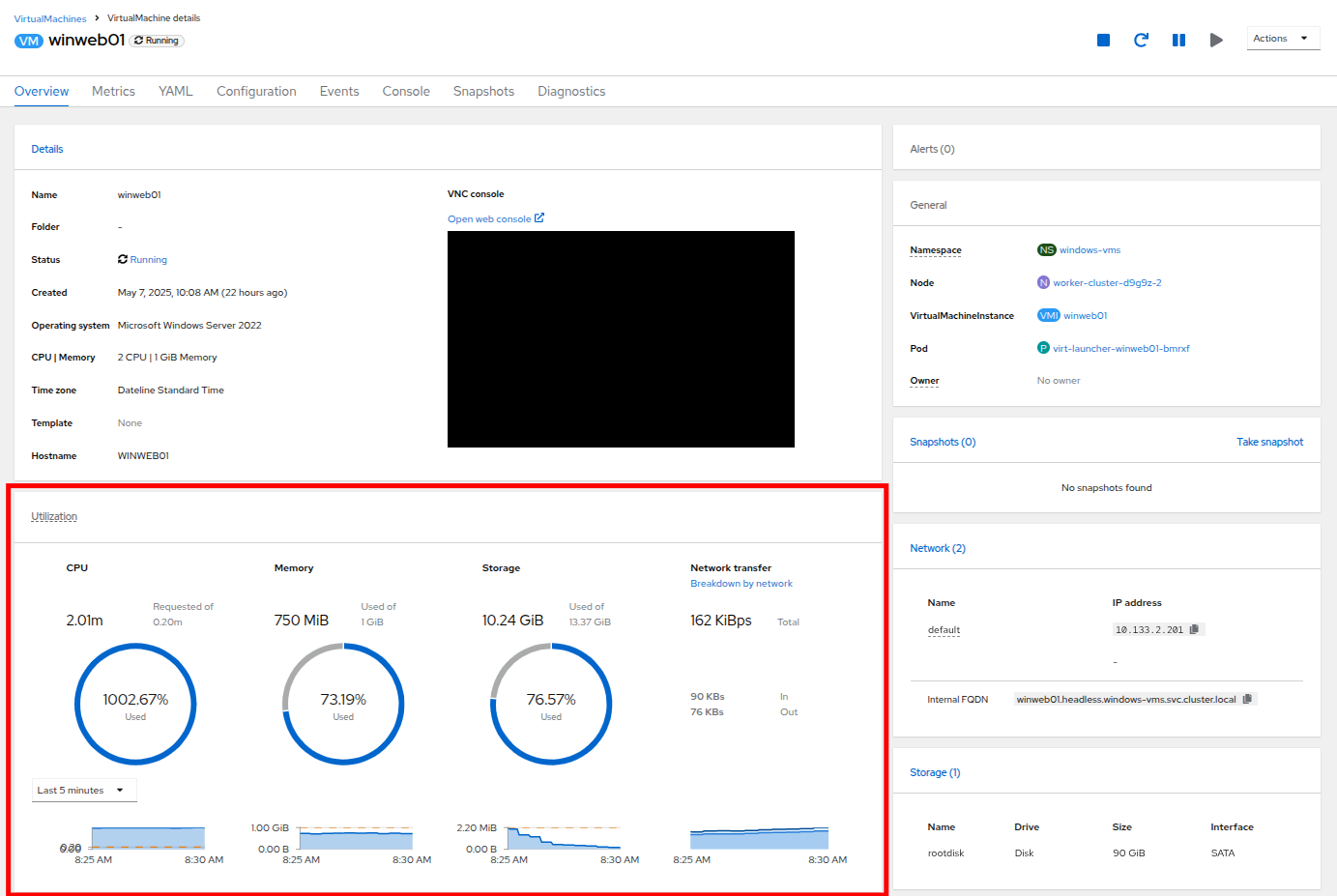 Figure 5. VM Details
Figure 5. VM Details -
metrics タブをクリックし、CPU 使用率グラフをざっと見てください。最大になっているはずです。
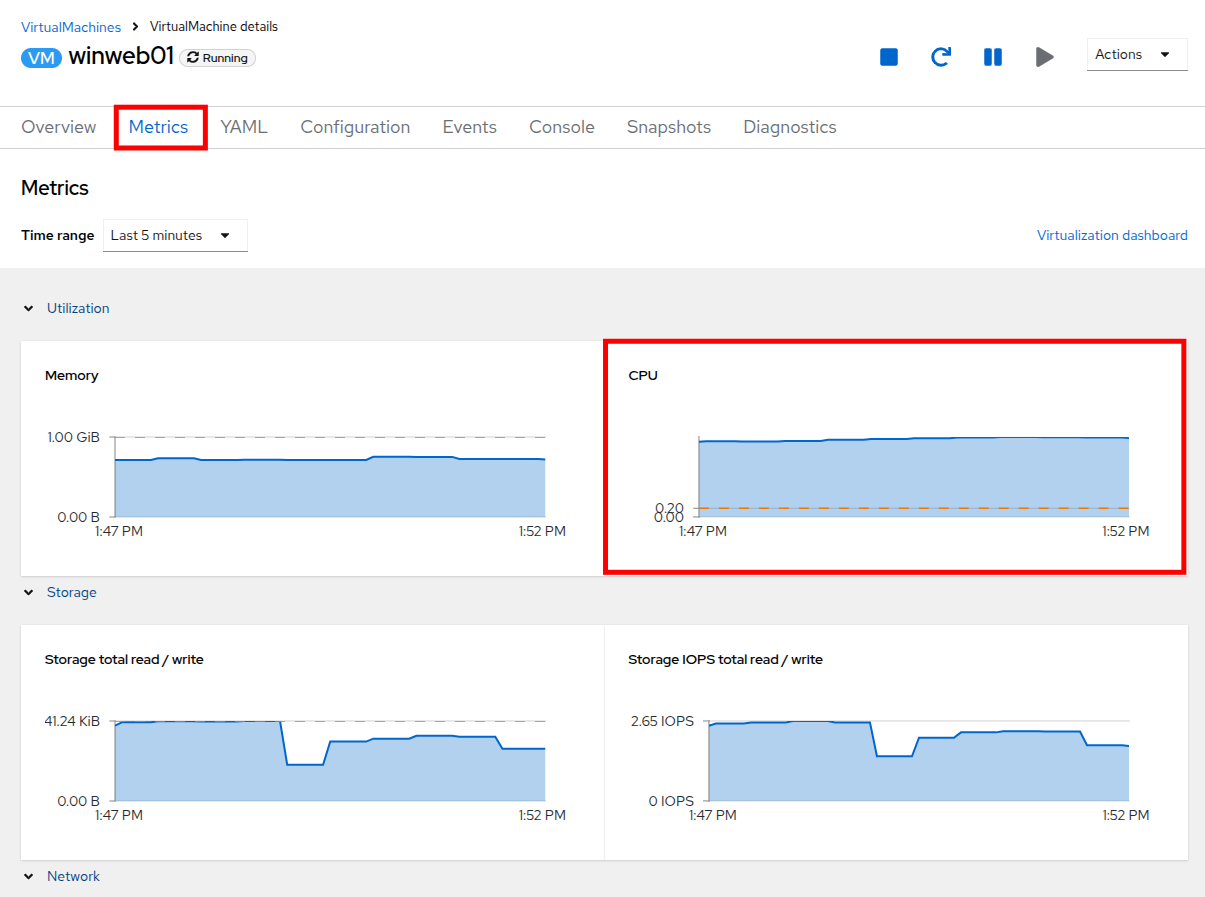 Figure 6. VM Metrics
Figure 6. VM Metrics -
CPU グラフ自体をクリックして展開バージョンを表示します。 サーバーの負荷が 1.0 (CPU 使用率 100%) を大幅に超えていることに気付くでしょう。これは、現時点で Web サーバーがひどく過負荷であることを意味します。
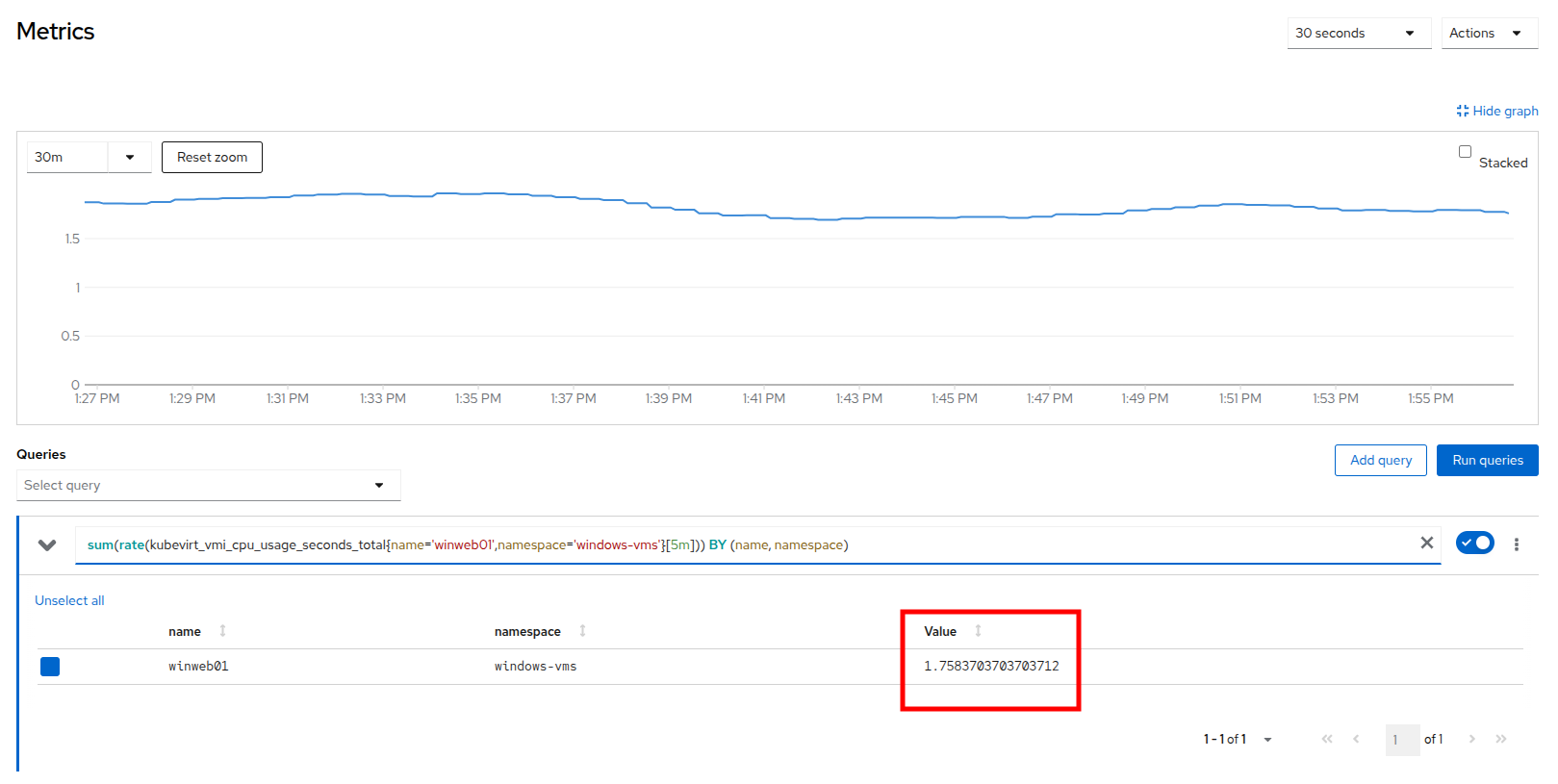 Figure 7. CPU Utilization and Load
Figure 7. CPU Utilization and Load
VM リソースの水平スケーリング
-
左側のナビゲーションメニューの VirtualMachines をクリックして仮想マシンのリストに戻り、winweb02 仮想マシンをクリックします。 VM がまだ Stopped 状態であることに注意してください。右上隅の Play ボタンを使用して仮想マシンを起動します。
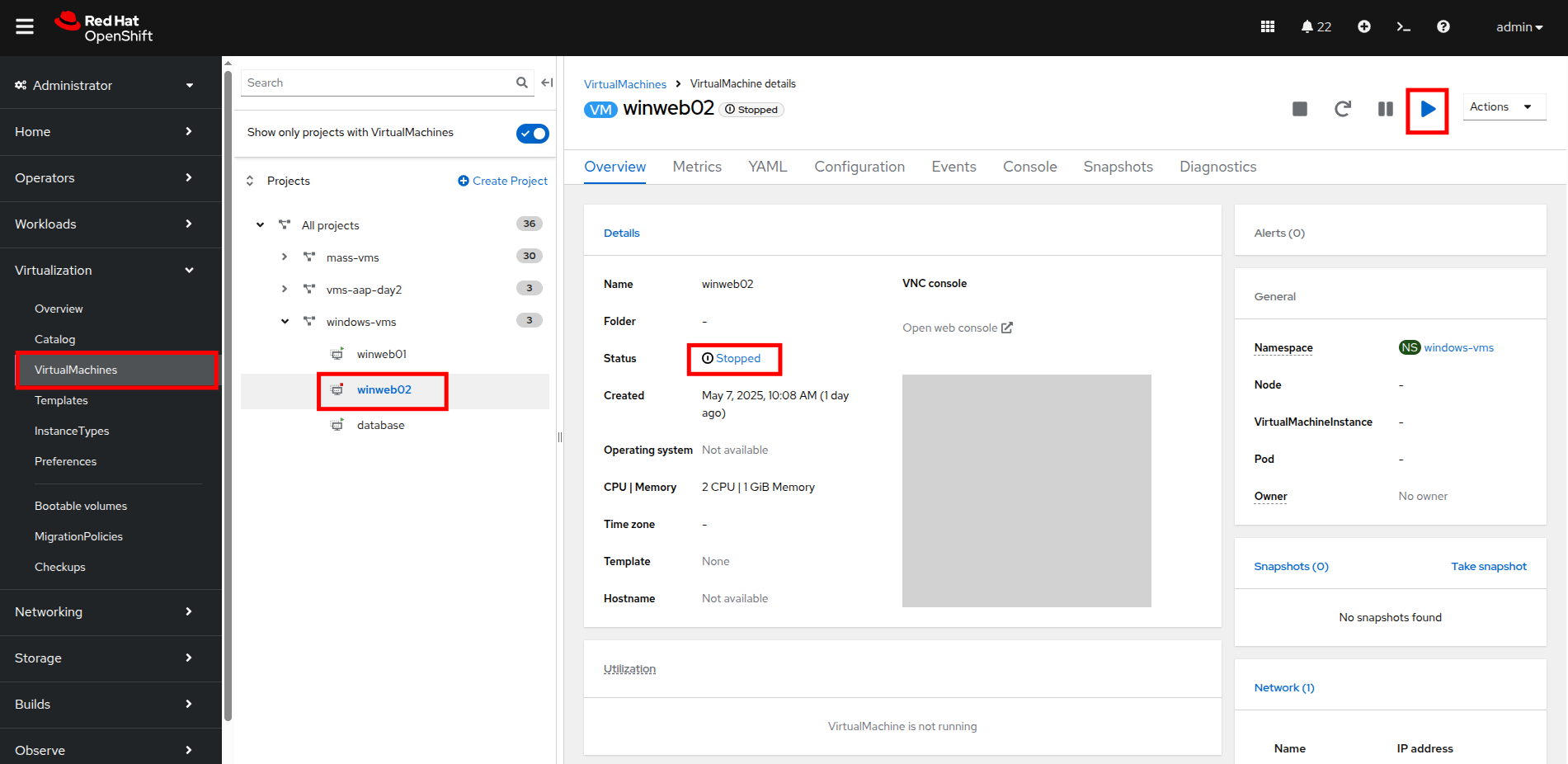 Figure 8. Power On Winweb02
Figure 8. Power On Winweb02 -
winweb01 仮想マシンの Metrics タブに戻り、もう一度その CPU グラフをクリックします。 負荷が徐々に下がり始めるはずです。
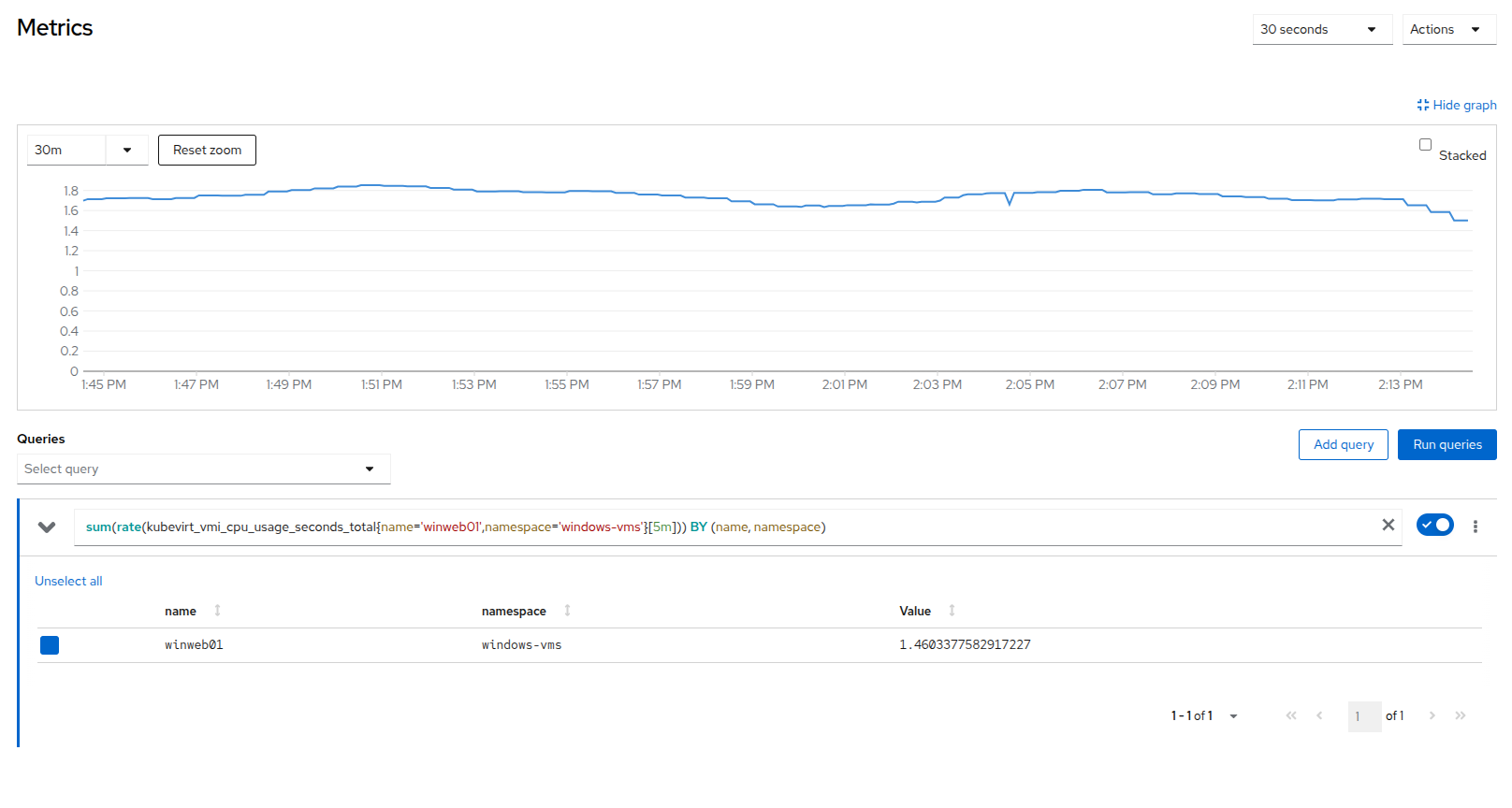 Figure 9. Load Reducing
Figure 9. Load Reducing -
Add query ボタンをクリックし、以下の構文を貼り付けて、winweb02 の負荷も同時にグラフ化します:
sum(rate(kubevirt_vmi_cpu_usage_seconds_total{name='winweb02',namespace='windows-vms'}[5m])) BY (name, namespace) -
Run queries ボタンをクリックし、更新されたグラフを確認します。
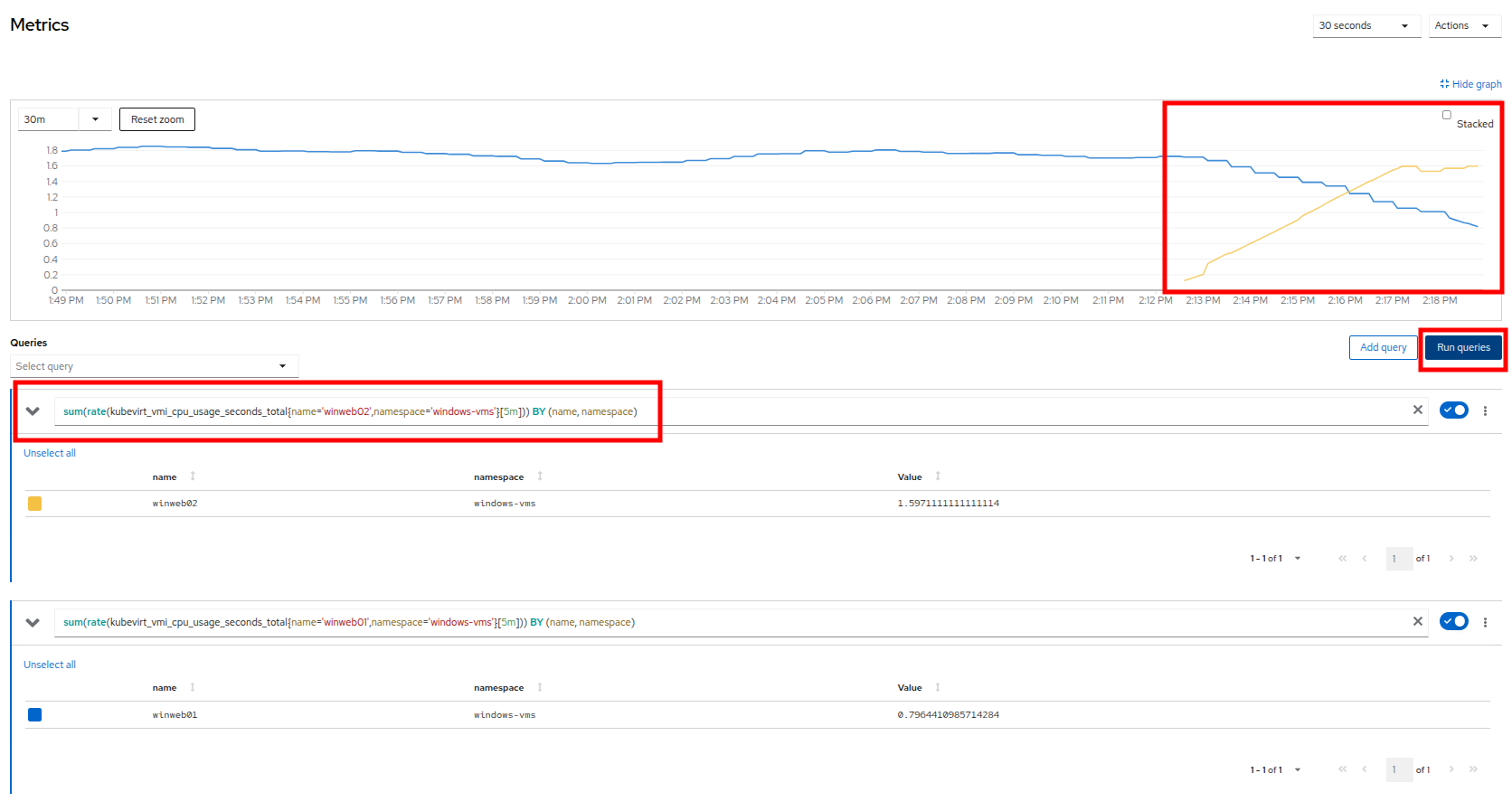 Figure 10. Load Sharing
Figure 10. Load Sharing
グラフを確認すると、winweb02 が winweb01 よりもはるかに大きな負荷にさらされていることがわかりますが、その後 5 分ほどで負荷は均等になり、2 台の仮想マシン間でバランスが取れるでしょう。
VM リソースの垂直スケーリング
5 分間隔で VM の負荷が均等になったとしても、依然としてかなり高い負荷がかかっていることがわかります。 これ以上水平スケーリングを行う能力がない場合、残された唯一の選択肢は、CPU とメモリーリソースを VM に追加することで垂直スケーリングを行うことです。 幸いなことに、前のモジュールで探求したように、これはこれらのリソースをホットプラグすることで実行でき、現在実行中のワークロードに影響を与えることはありません。
-
前のセクションのメトリックページにあるグラフを確認することから始めます。 左上隅のドロップダウンを使用して、更新間隔を過去 5 分に設定できます。 2 つの仮想ゲストの負荷が 1.0 付近で安定しており、両方のゲストが依然としてかなり圧倒されていることを示していることに注意してください。
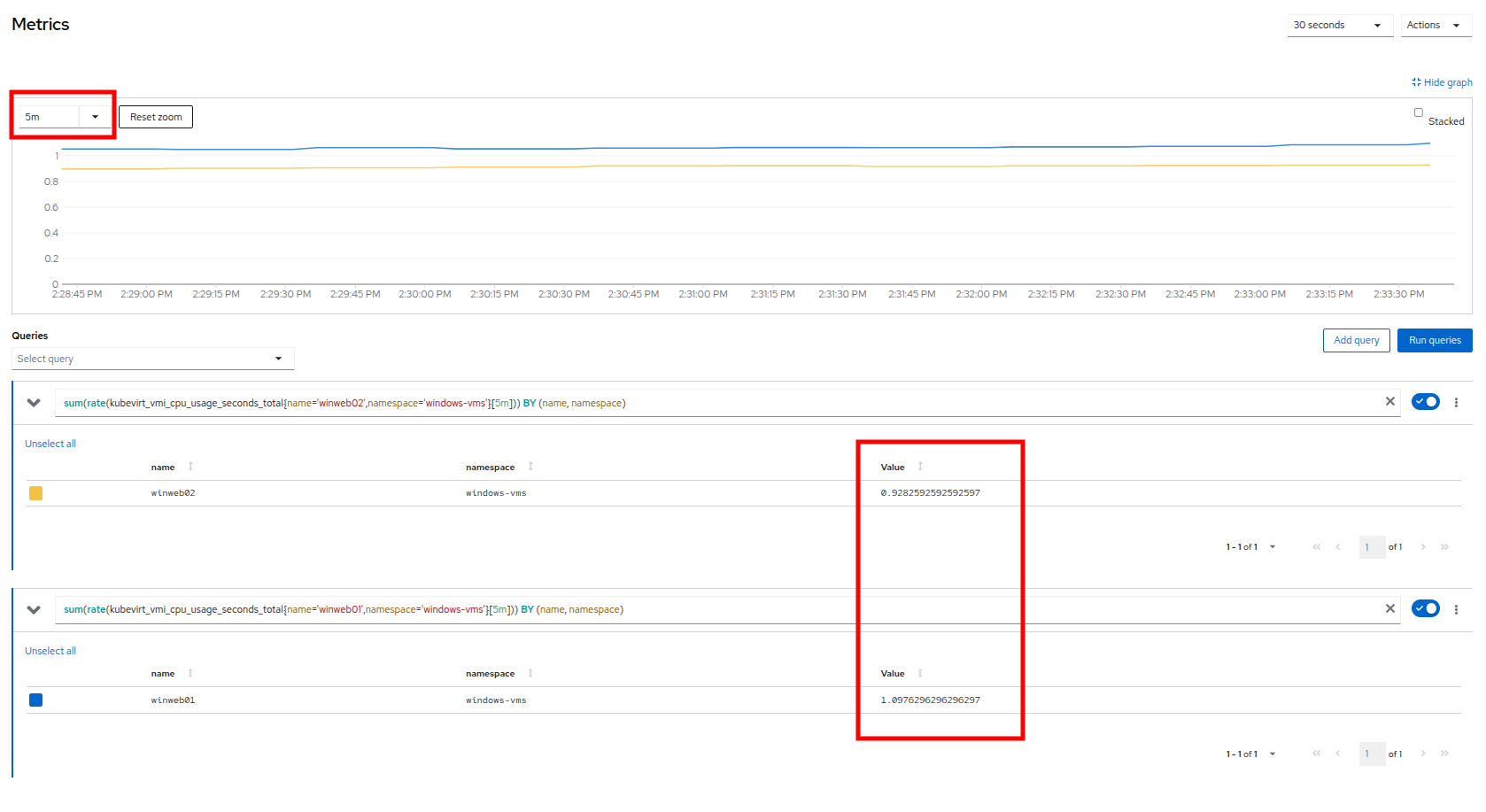 Figure 11. Balanced Load
Figure 11. Balanced Load -
左側のナビゲーションメニューの VirtualMachines をクリックして仮想マシンリストに戻り、winweb01 をクリックします。
 Figure 12. Select VM
Figure 12. Select VM -
VM の Configuration タブをクリックし、VirtualMachine details の下の CPU|Memory セクションを見つけ、鉛筆アイコンをクリックして編集します。
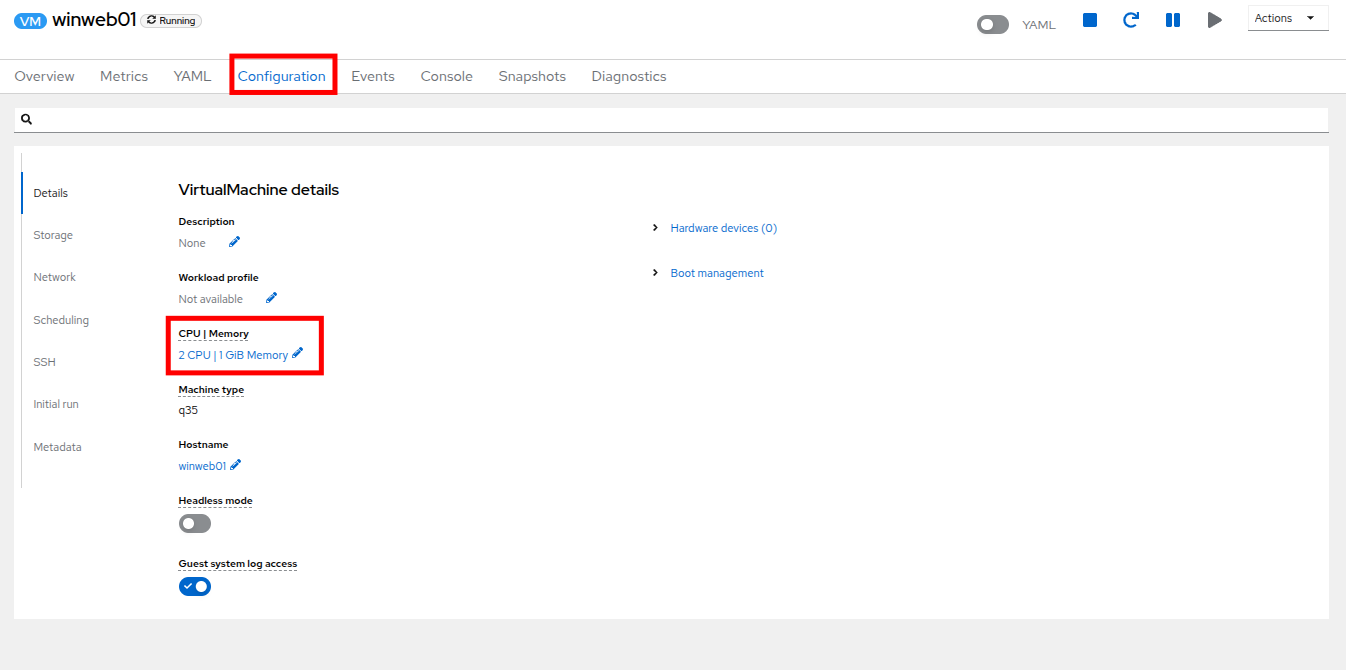 Figure 13. Edit VM
Figure 13. Edit VM -
vCPU を 4 に増やし、Save ボタンをクリックします。
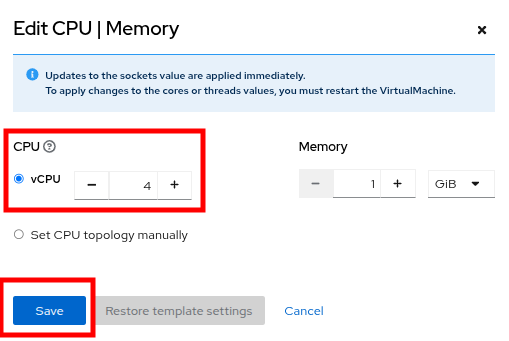 Figure 14. Update Specs
Figure 14. Update Specs -
Overview タブに戻ります。詳細の CPU|Memory セクションが新しい値に更新されており、ゲストの CPU 使用率が徐々にかなり速く低下していることがわかるでしょう。
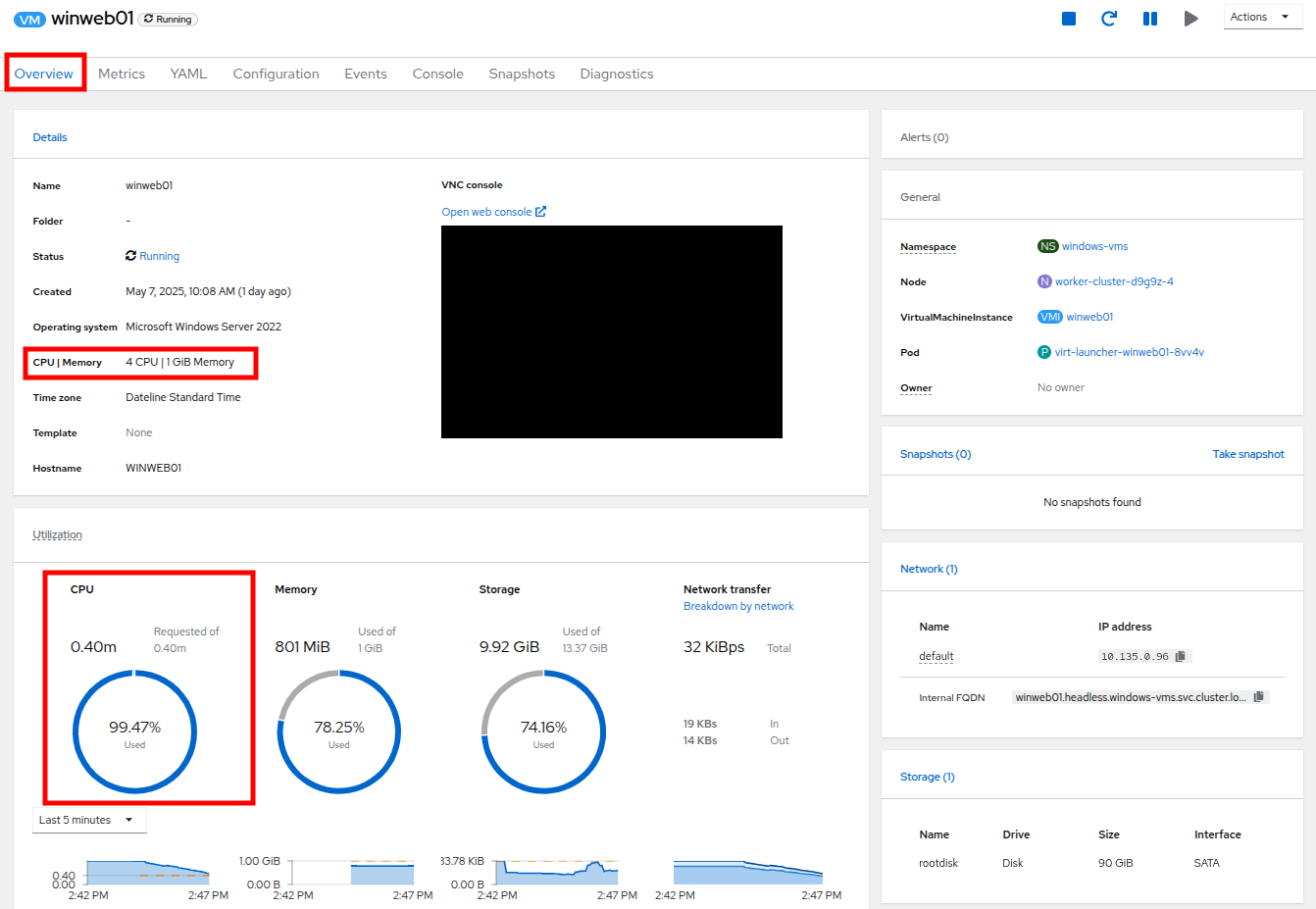 Figure 15. New VM Spec
Figure 15. New VM Spec -
winweb02 についてもこれらの手順を繰り返します。
-
両方の VM がアップグレードされたら、windows-vms プロジェクトをクリックします。CPU 使用率が劇的に低下したことがわかるでしょう。
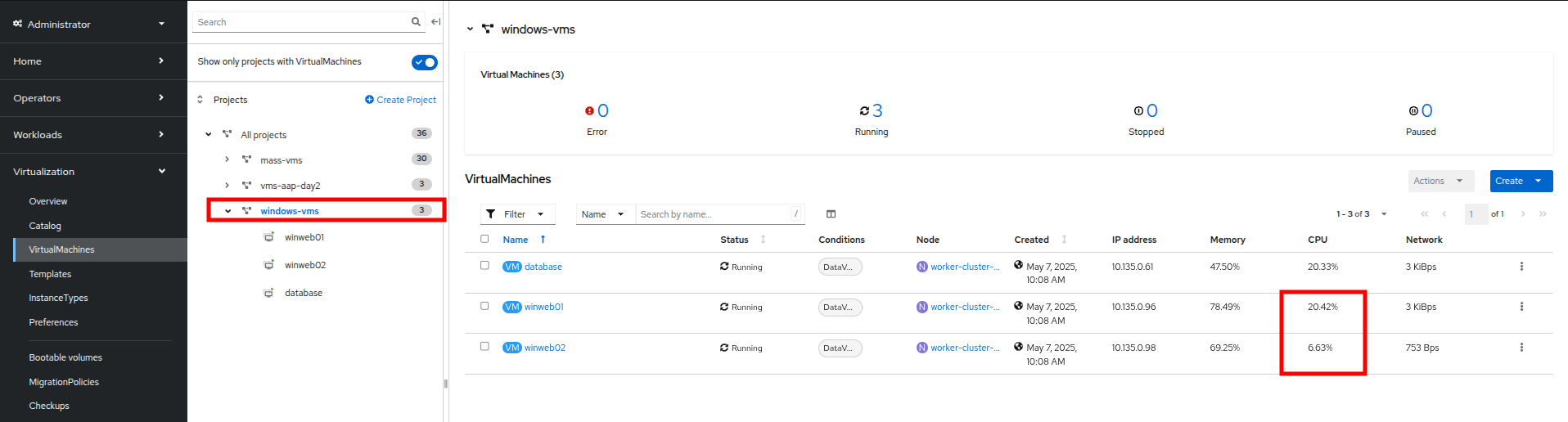 Figure 16. Updated Utilization
Figure 16. Updated Utilization -
winweb01 をクリックし、次に Metrics タブと CPU グラフをクリックして、使用率グラフが現在どのように見えるかを確認します。 winweb02 からのクエリを再度追加することもでき、各ゲストのリソースが増加した後、両方のグラフが非常に急速に低下し、各 VM の負荷が以前よりもはるかに少なくなったことがわかります。
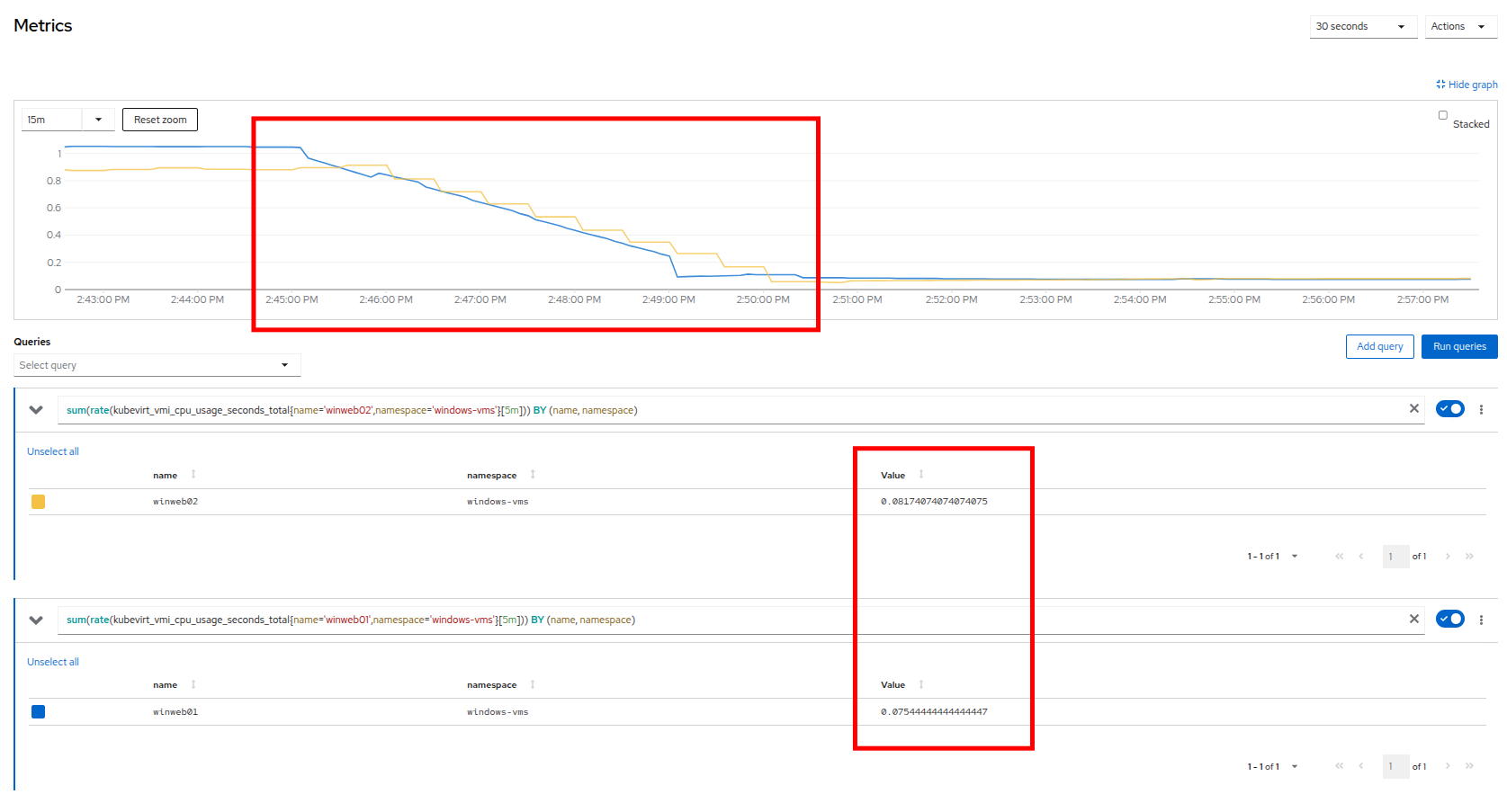 Figure 17. Verify Metrics
Figure 17. Verify Metrics
スワップ/メモリーのオーバーコミットに関する考察
| このラボのセクションは、物理クラスターリソースが不足している状況で実行する可能性があることに関する情報提供のみを目的としています。 以下の情報をお読みください。 |
物理リソースをすべて使い果たしたため、特定のワークロードの CPU またはメモリーリソースを増やす能力がない場合があります。 デフォルトでは、OpenShift の CPU のオーバーコミット比率は 10:1 ですが、Kubernetes 環境のメモリーは多くの場合有限のリソースです。
通常の Kubernetes クラスターが高いワークロードリソース使用率のためにメモリー不足のシナリオに遭遇すると、無差別に Pod を強制終了し始めます。 コンテナーベースのアプリケーション環境では、これは通常、ロードバランサーサービスの背後にアプリケーションの複数のレプリカを持つことで軽減されます。 アプリケーションは他のレプリカによって提供され続け、強制終了された Pod は空きリソースを持つノードに再割り当てされます。
これは、ほとんどの場合、多数のレプリカで構成されておらず、永続的に利用可能である必要がある仮想マシンワークロードにはあまり効果的ではありません。
クラスター内の物理リソースを使い果たした場合の従来の手段は、クラスターをスケーリングすることですが、これは言うは易く行うは難しの場合が多くあります。 予備の物理ノードが待機しておらず、新しいハードウェアを注文する必要がある場合、調達手順やサプライチェーンの混乱によって遅延することがよくあります。
これに対する 1 つの回避策は、新しいハードウェアが到着するまで時間を稼ぐために、一時的にノードで SWAP/メモリーのオーバーコミットを有効にすることです。 これにより、ワーカーノードが SWAP し、ハードディスクスペースを使用してアプリケーションメモリーを書き込むことができます。 ハードディスクへの書き込みはシステムメモリーへの書き込みよりもはるかに遅いですが、追加のリソースが到着するまでワークロードを維持することができます。
ノード追加によるクラスターのスケーリング
クラスターの物理リソースが不足した場合の主な手段は、追加のワーカーノードを追加してクラスターをスケーリングすることです。 これにより、失敗しているワークロードや割り当てることができないワークロードを正常に割り当てることができるようになります。 このラボのセクションはまさにこの考えに特化しており、クラスターに過負荷をかけ、新しいノードを追加してすべての VM が正常に実行できるようにします。
| このラボ環境では、実際に追加の物理ノードを追加しているわけではなく、VM ワークロードを許可しないようにテイントされた待機中のノードを用意することで動作をシミュレートしています。 適切なタイミングでこのテイントを削除することで、クラスターへの新しいノードの追加をシミュレートします。 |
-
左側のナビゲーションメニューで、Virtualization、次に VirtalMachines をクリックします。
-
vms-aap-day2 および windows-vms プロジェクトのすべての VM の電源がオンになっていることを確認します。
 Figure 18. Verify Running VMs
Figure 18. Verify Running VMs -
mass-vm プロジェクトをクリックして、そこにある仮想マシンを一覧表示します。 1 - 15 of 30 ドロップダウンをクリックし、50 per page に変更してすべての VM を表示します。
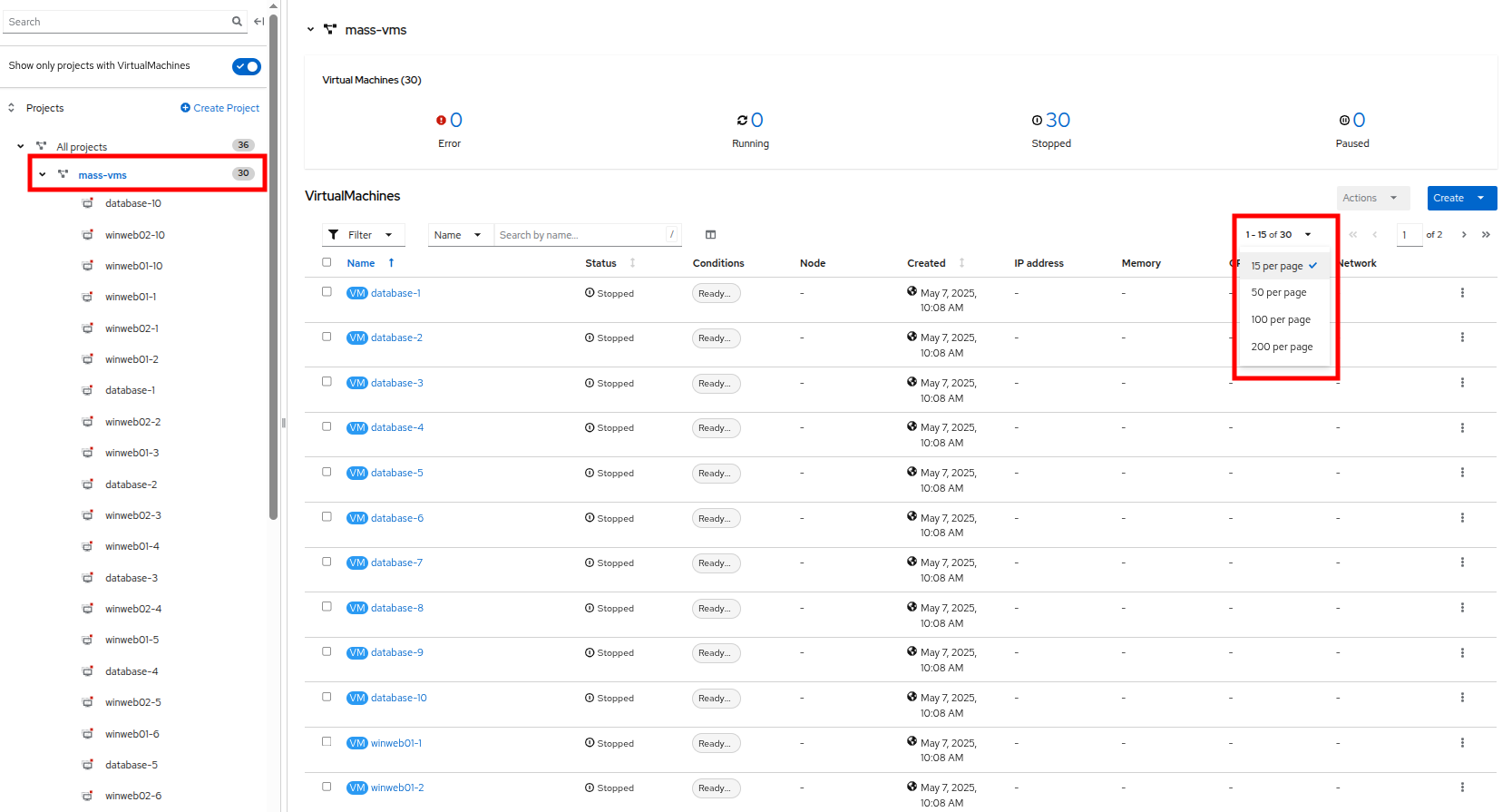 Figure 19. Mass VMs Project
Figure 19. Mass VMs Project -
Filter ドロップダウンの下にあるチェックボックスをクリックして、プロジェクト内のすべての VM を選択します。 Actions ボタンをクリックし、ドロップダウンメニューから Start を選択します。
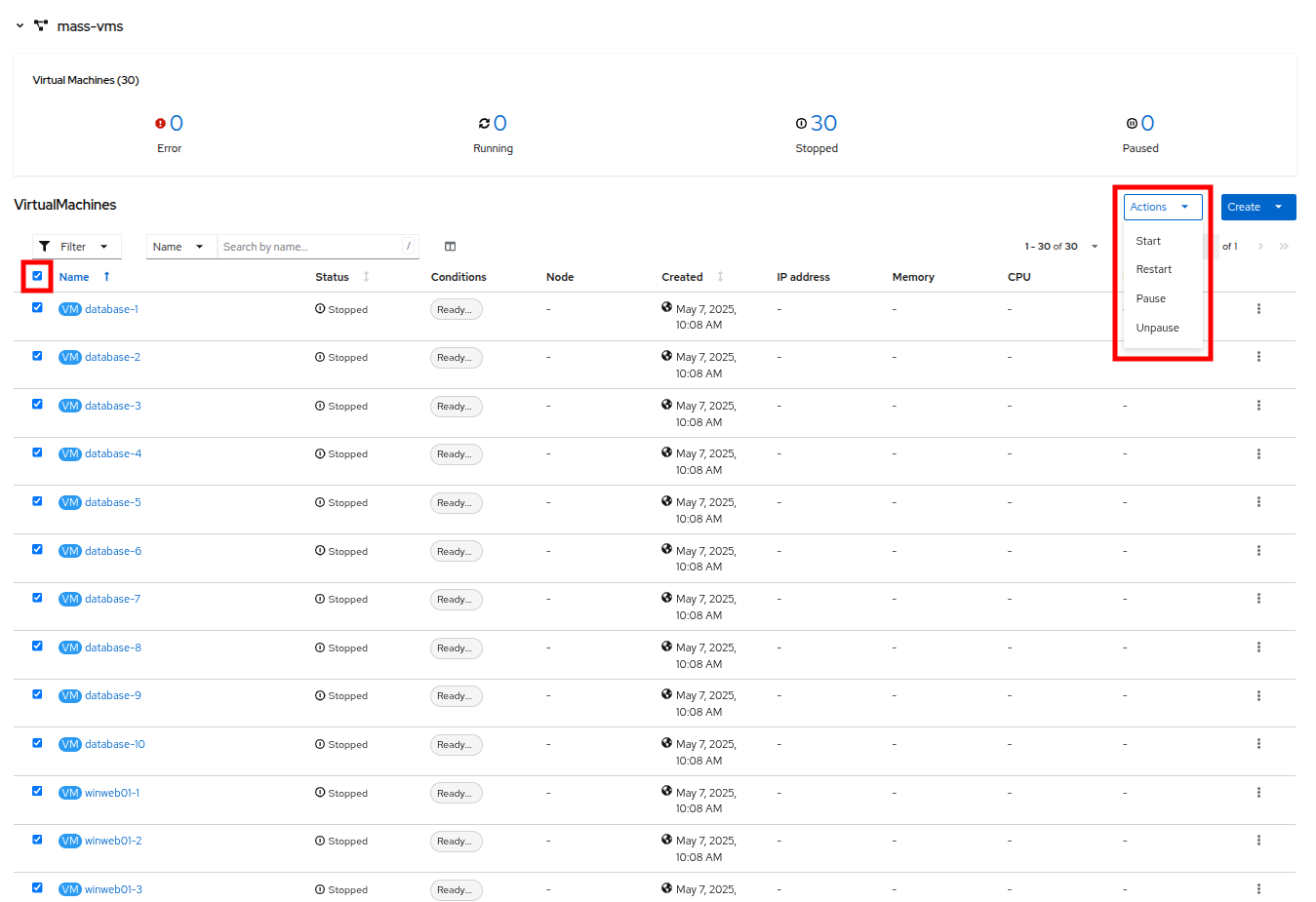 Figure 20. Start All VMs
Figure 20. Start All VMs -
すべての VM が起動しようとすると、約 6〜7 台の VM が現在エラー状態になっているはずです。
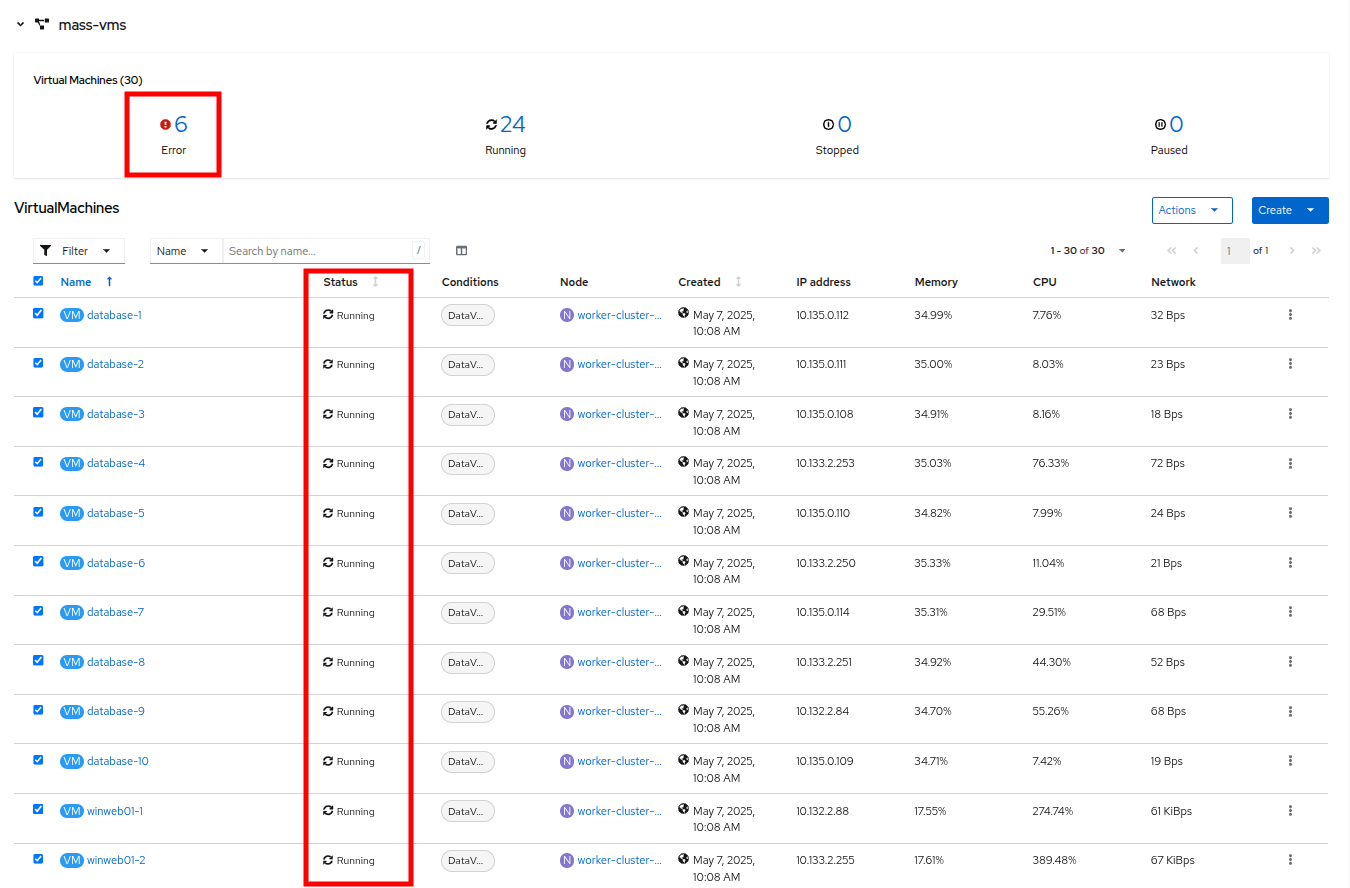 Figure 21. VMs After Startup
Figure 21. VMs After Startup -
エラーの数をクリックして、エラー状態の説明を確認します。
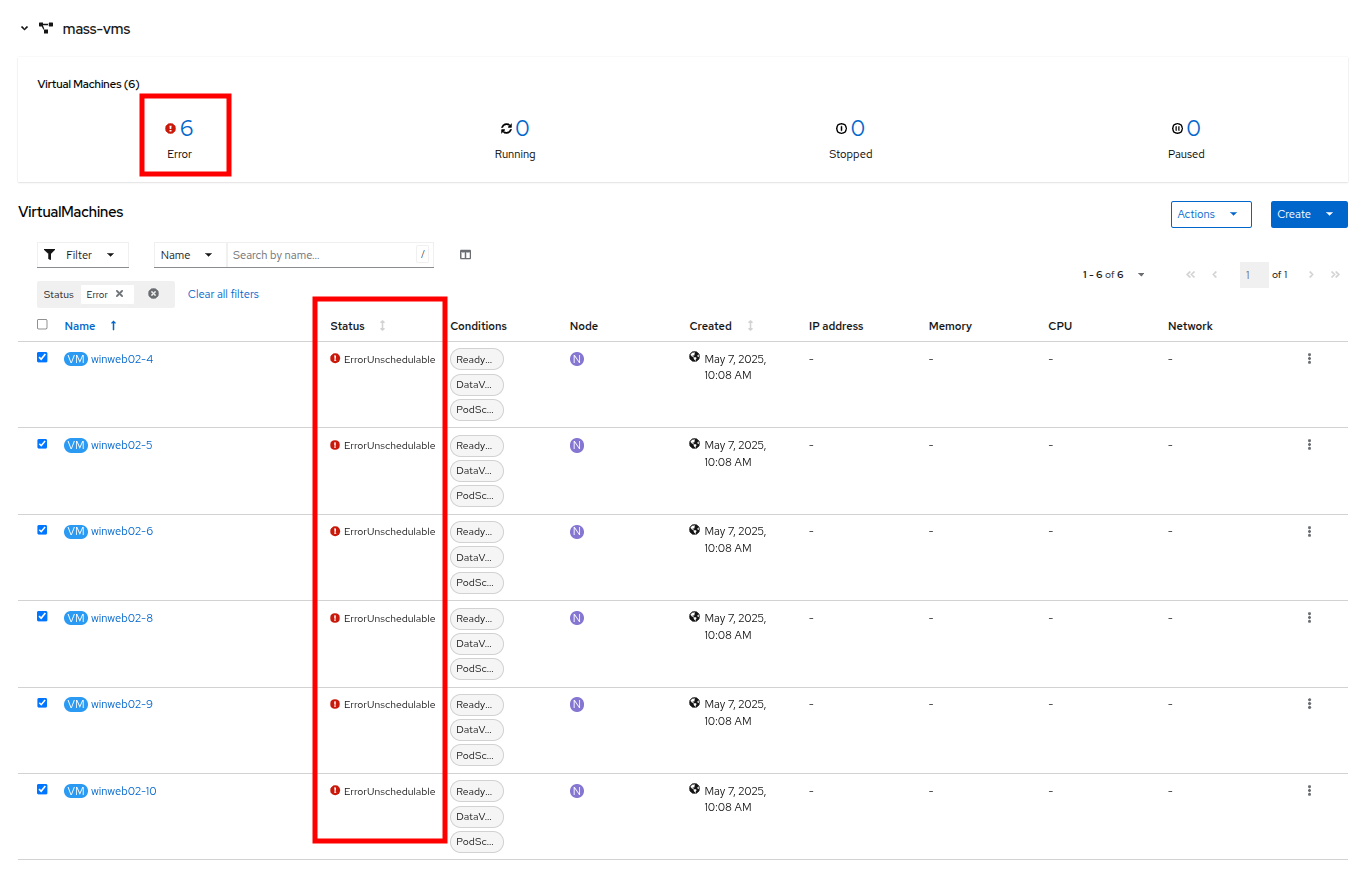 Figure 22. Error Details
Figure 22. Error Details -
これらの VM はそれぞれ、クラスターがそれらをスケジュールするためのリソース不足のため、ステータス列に ErrorUnschedulable を表示するでしょう。
-
左側のナビゲーションメニューで、Compute、次に Nodes をクリックします。 3 つのワーカーノード(ノード 2〜4)には多数の割り当てられた Pod と大量の使用済みメモリーがあり、ワーカーノード 1 はそれと比較して使用量がはるかに少ないことがわかります。
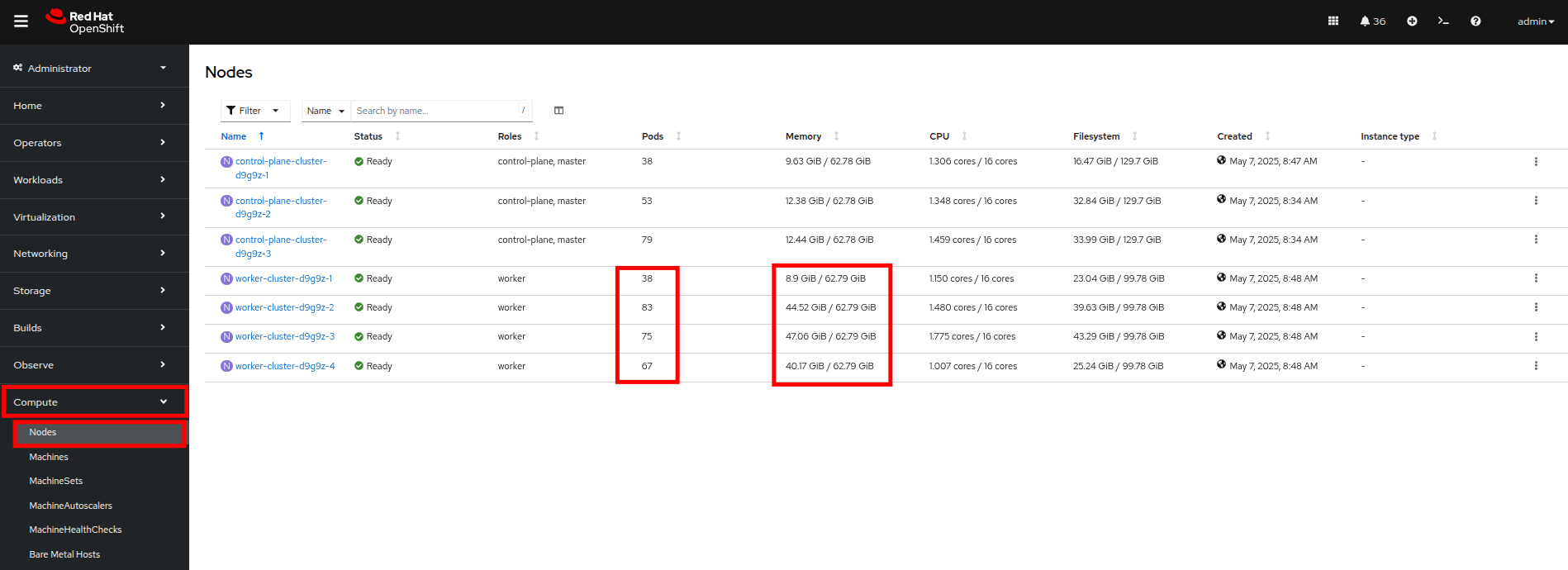 Figure 23. Nodes
Figure 23. NodesOpenShift 環境では、利用可能なメモリーは各 Pod によって提出されたメモリー要求に基づいて計算されます。 このようにして、Pod がその時点でその量を使用していなくても、Pod が必要とするメモリーは保証されます。 これが、これらのワーカーノードがそれぞれ、見ても約 75% の使用率しか示していないにもかかわらず、「満杯」と見なされる理由です。 -
ワーカーノード 2 をクリックすると、Node details ページに移動します。 ノードで利用可能なリソースが制限されていることに関する警告があることに注意してください。 使用済みメモリーが青色で表示され、要求された量がオレンジ色の破線としても表示される、ノードのメモリー使用率のグラフも確認できます。
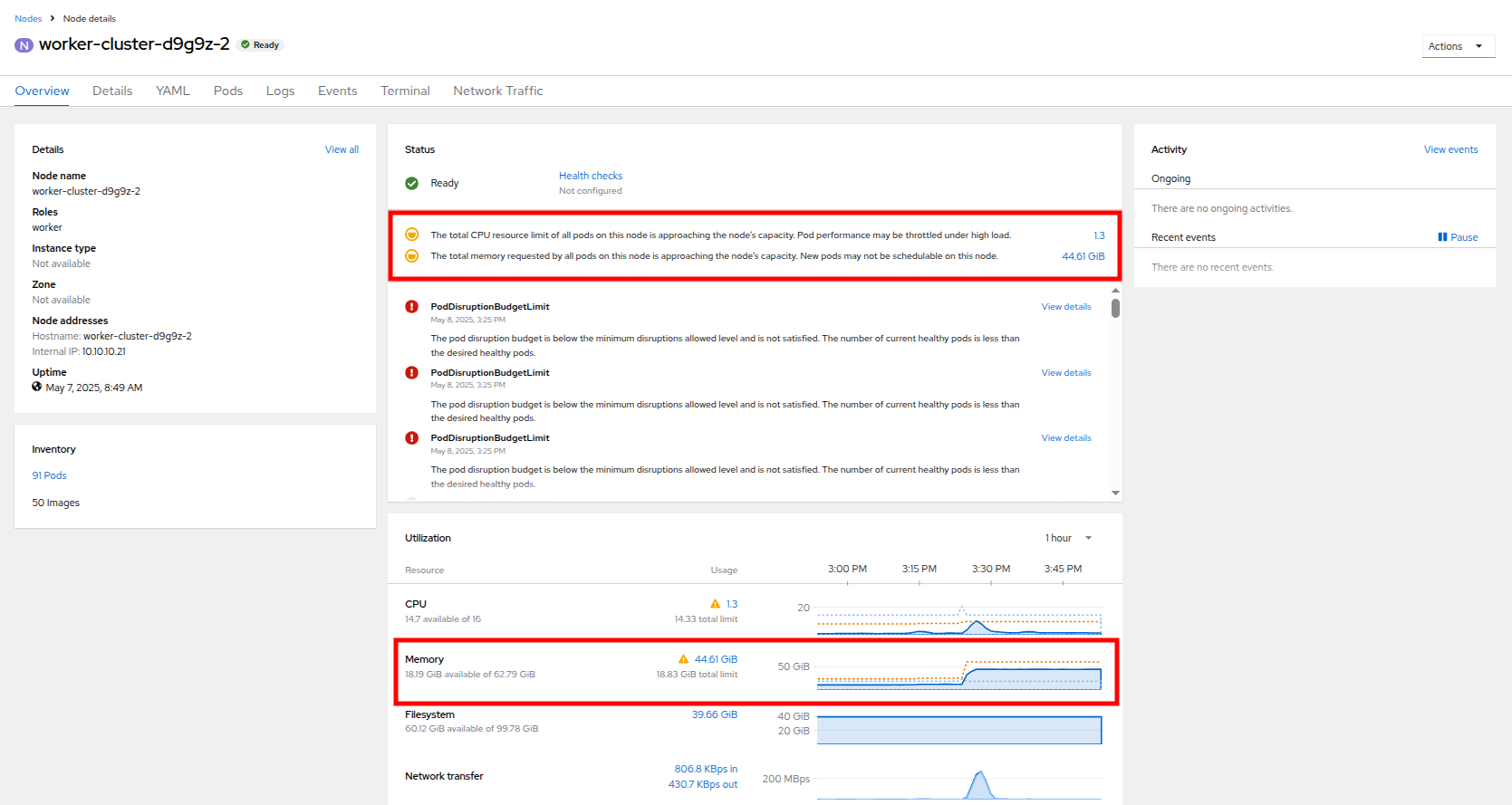 Figure 24. Worker Node 2 Details
Figure 24. Worker Node 2 Details -
上部の Pods タブをクリックし、検索バーに
virt-launcherと入力して、ノード上の VM を検索します。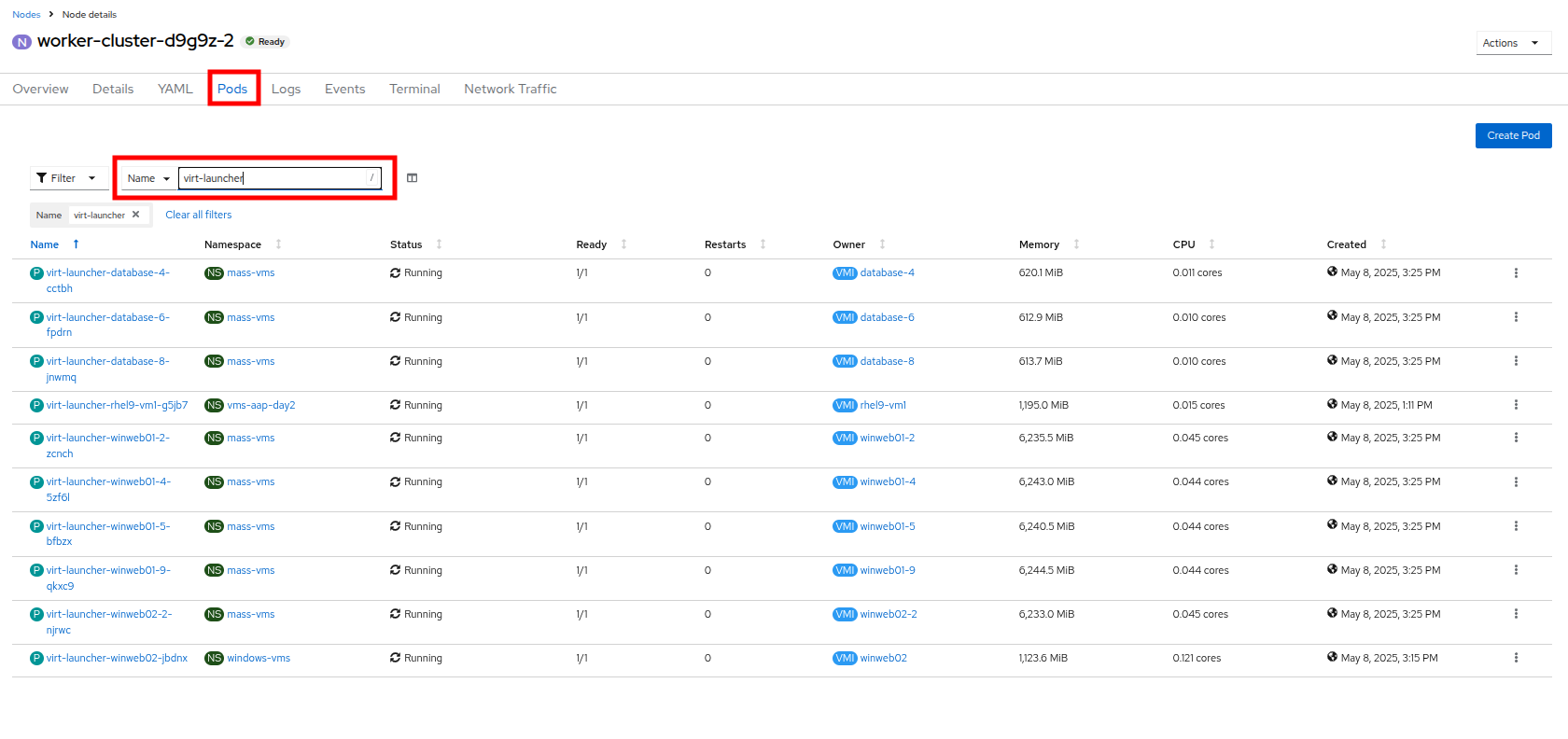 Figure 25. VMs On Worker Node 2
Figure 25. VMs On Worker Node 2 -
次に、左側のナビゲーションメニューの Nodes をクリックし、次にワーカーノード 1 をクリックすると、その Node details ページに移動します。 現在、ノードに CPU またはメモリーの警告がないことに注意してください。
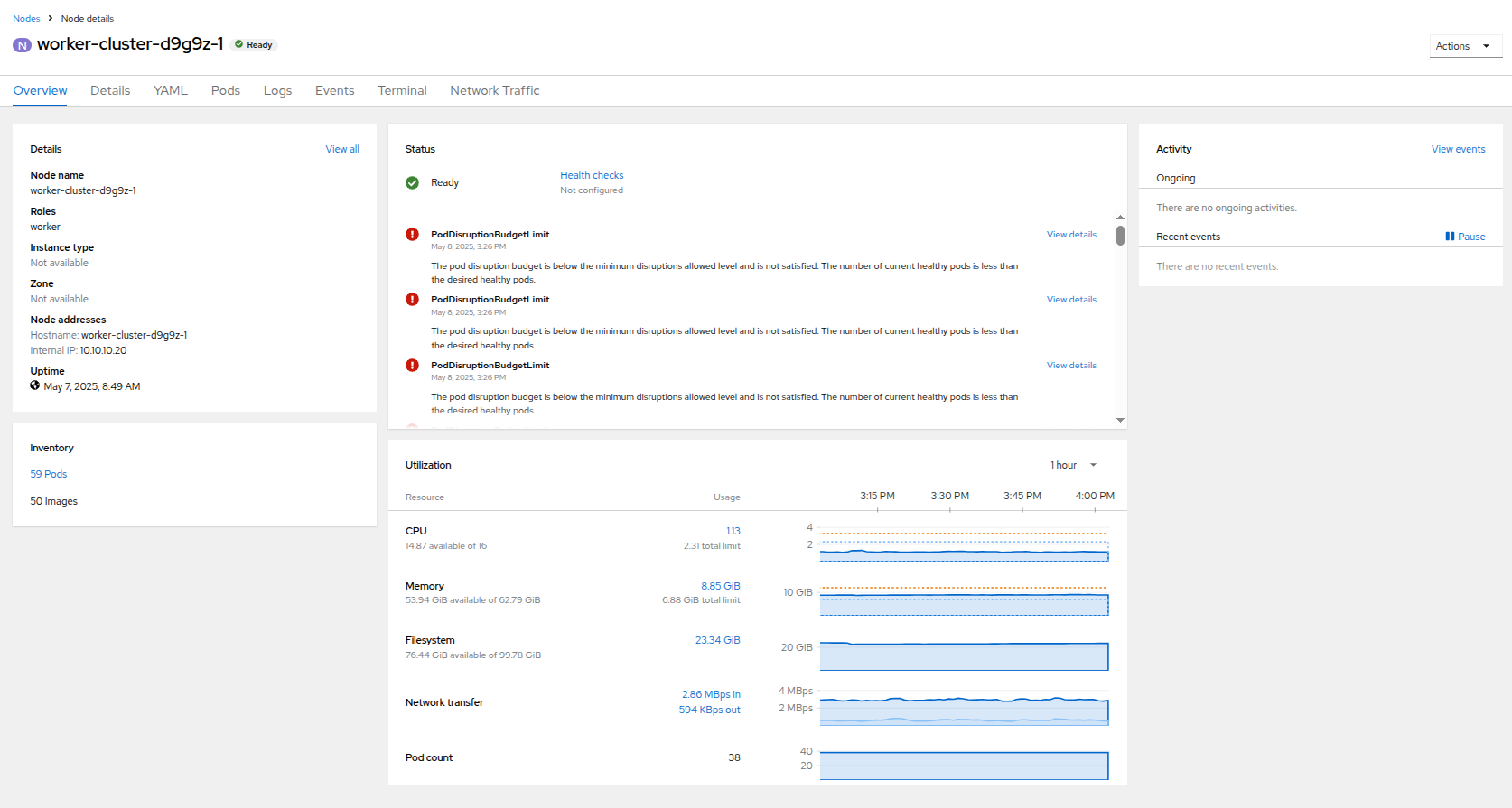 Figure 26. Worker Node 1 Details
Figure 26. Worker Node 1 Details -
上部の Pods タブをクリックし、検索バーに
virt-launcherと入力してノード上の VM を検索します。 現在、VM がないことに注意してください。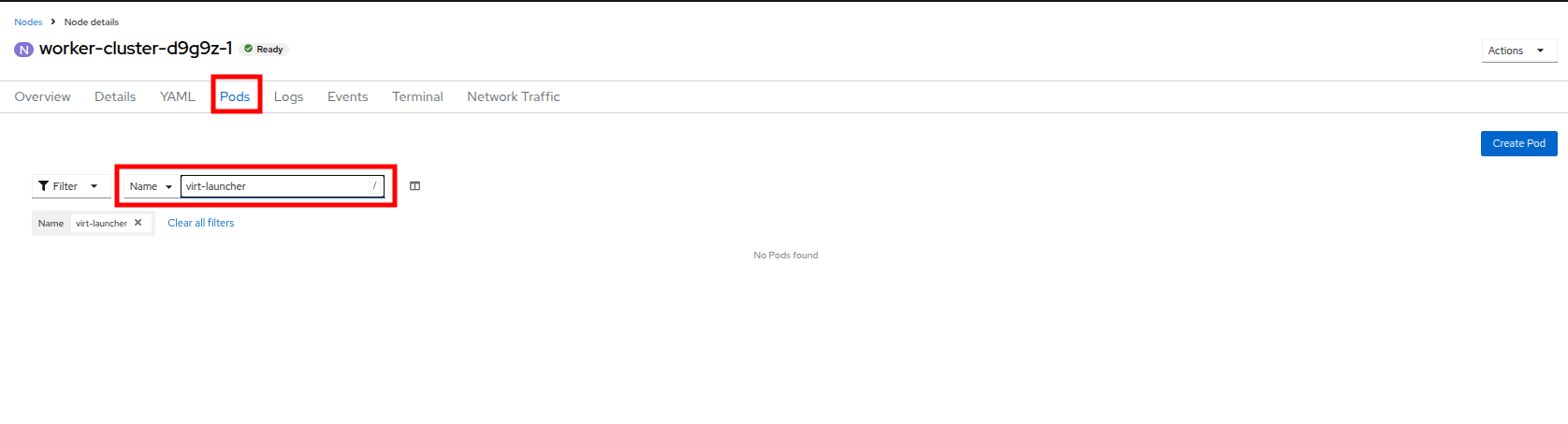 Figure 27. VMs On Worker Node 1
Figure 27. VMs On Worker Node 1 -
Details タブをクリックし、スクロールダウンして Taints セクションが表示されるまで移動します。そこには 1 つのテイントが定義されています。
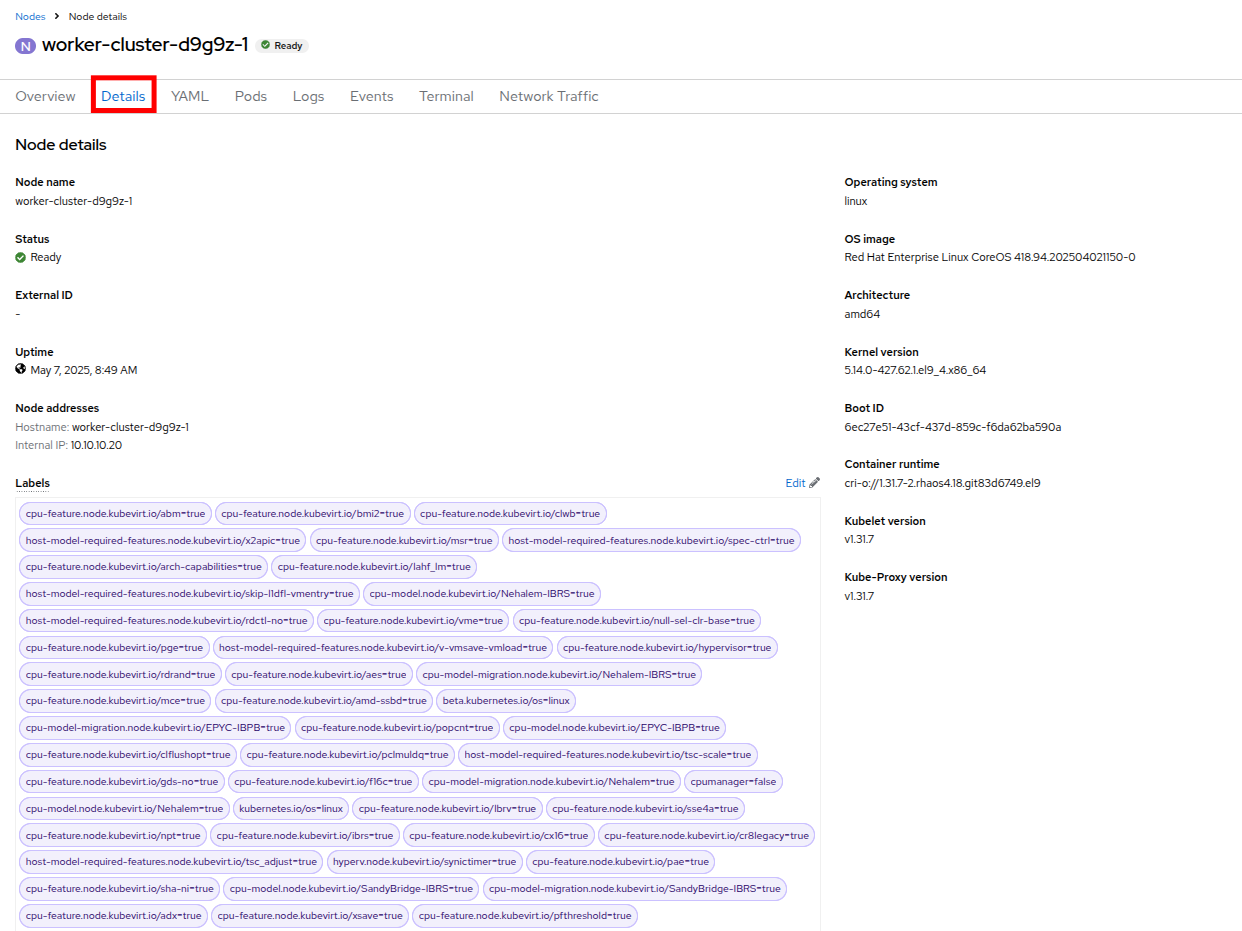 Figure 28. Node Details
Figure 28. Node Details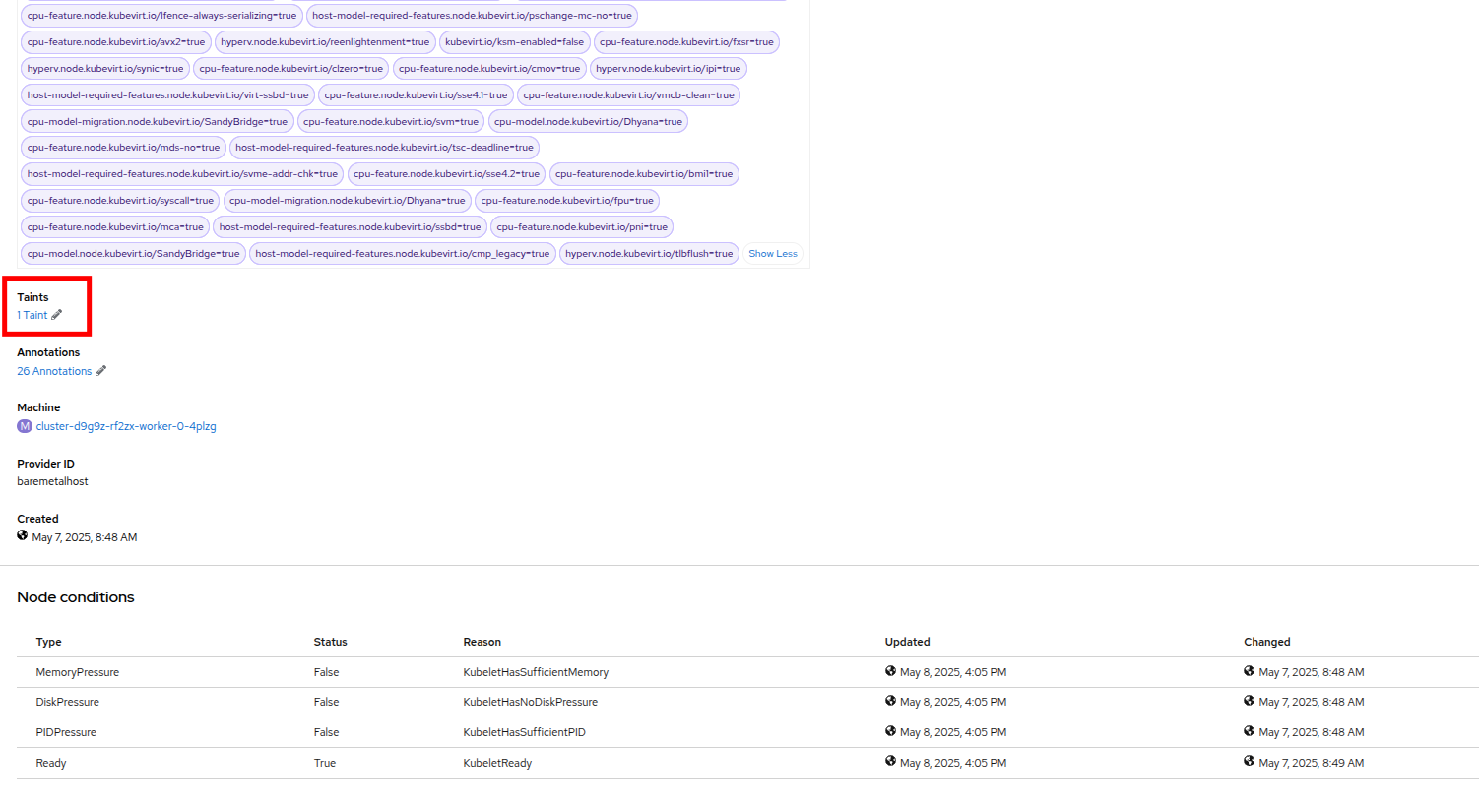 Figure 29. Select Taints
Figure 29. Select Taints -
鉛筆 アイコンをクリックして、ノード上の現在の Taint を編集するためのボックスを表示します。 ボックスが表示されたら、テイント定義の横にある - をクリックして削除し、Save ボタンをクリックします。
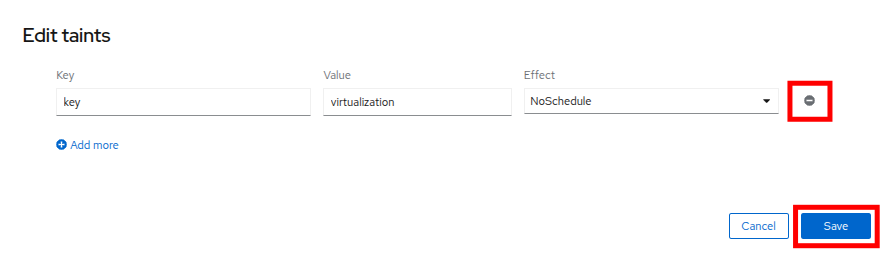 Figure 30. Remove Taint
Figure 30. Remove Taint -
テイントが削除されたら、上部に戻って Pods タブをもう一度クリックし、検索バーに
virt-launcherと入力すると、スケジュール不可能だった VM がこのノードに割り当てられていることがわかります。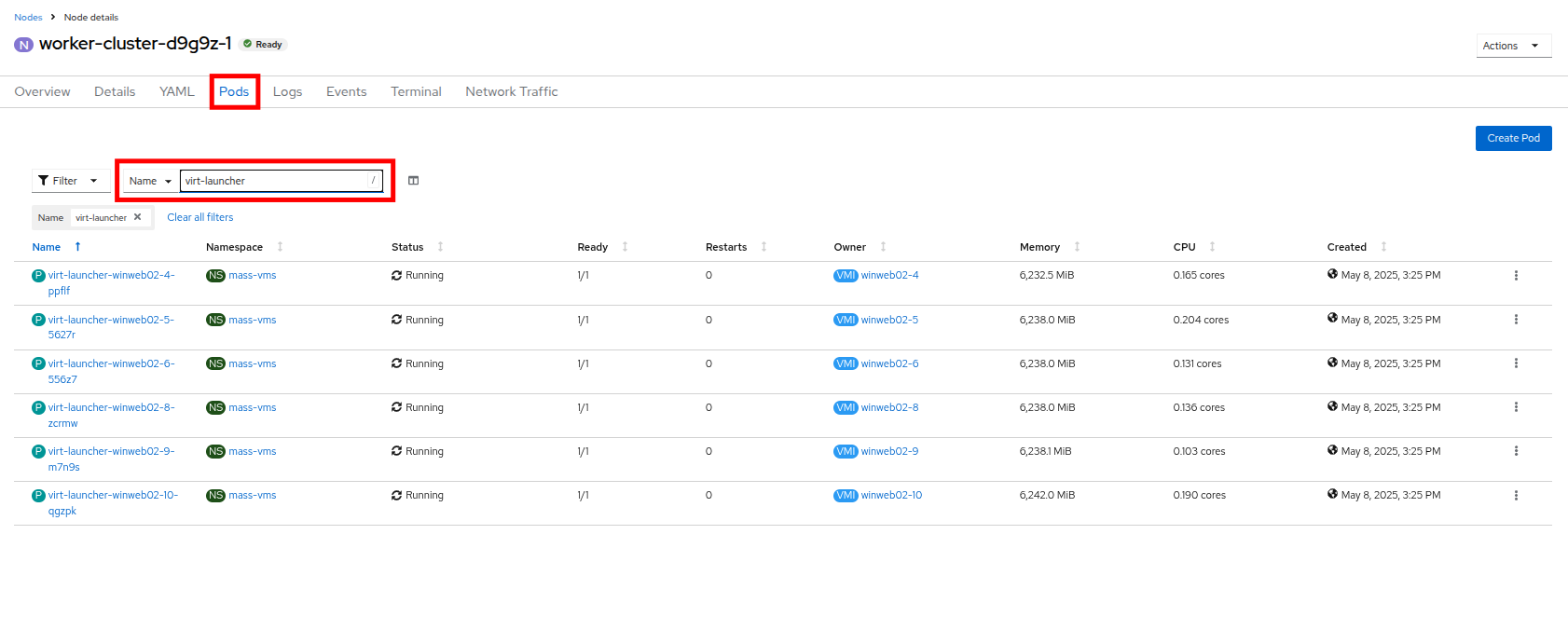 Figure 31. VMs On Worker Node 1
Figure 31. VMs On Worker Node 1 -
左側のナビゲーションメニューの Virtualization、次に VirtualMachines をクリックして mass-vms プロジェクトの VM のリストに戻り、すべての VM が実行中になっていることを確認します。
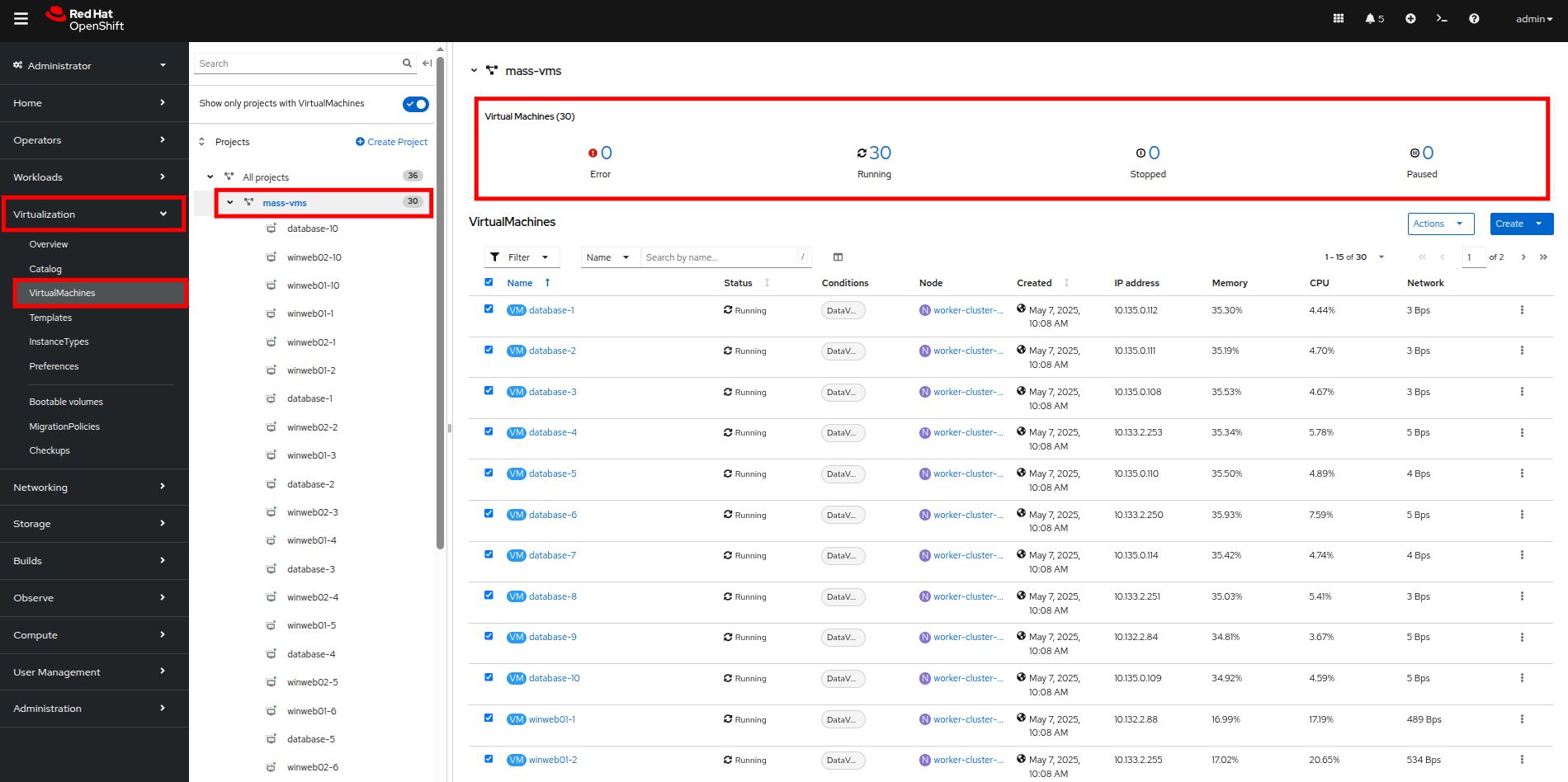 Figure 32. Mass VMs Running
Figure 32. Mass VMs Running